SQL优化技巧 - PawSQL的智能索引推荐,帮助窗口函数性能提升50倍

🌟 引言
在数据驱动的现代世界,SQL查询的速度是应用程序快速响应的关键。尤其是那些涉及窗口函数的复杂查询,若缺乏恰当的索引支持,性能瓶颈可能会成为阻碍。本文将带您一探究竟,看看PawSQL是如何通过智能索引推荐,显著提高包含窗口函数的SQL查询性能的。
🔍 案例分析
通过一个实际案例,我们将展示PawSQL如何优化一个包含窗口函数的查询。
📝 原始查询
SELECT *
FROM (
SELECT o.o_custkey, o.o_totalprice,
RANK() OVER (PARTITION BY o.o_custkey ORDER BY o.o_totalprice) AS rn
FROM orders AS o
WHERE o.o_orderdate = '1996-06-20'
) AS A
WHERE A.rn = 1
此查询旨在找出1996年6月20日这一天,每个客户的最低订单金额。
🎩 PawSQL的优化秘籍
PawSQL对查询进行了深入分析,并提出了以下�优化建议:
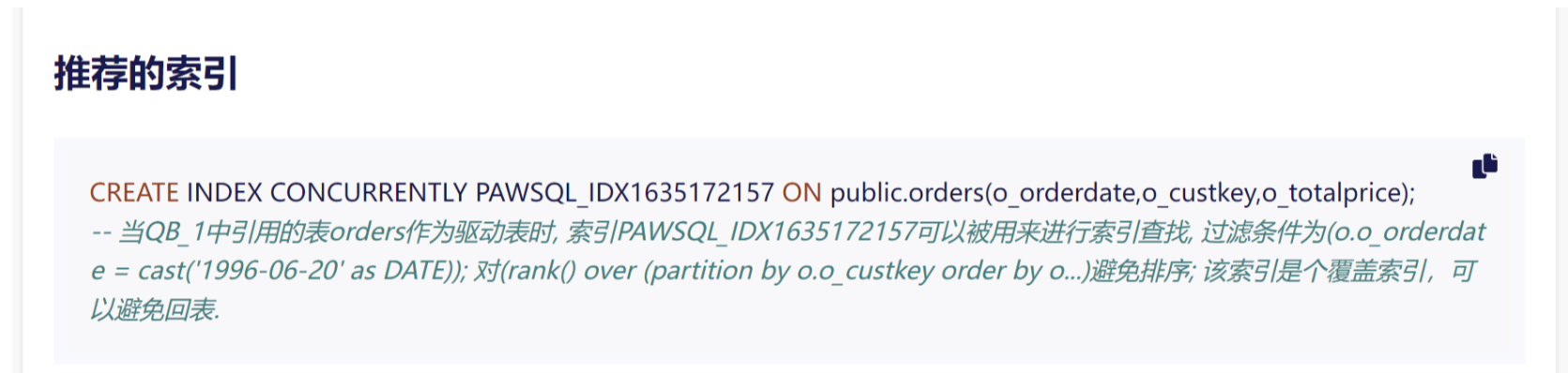
🌈 性能提升的秘诀
优化详情的页面可以看到,PawSQL推荐的索引能够将查询性能提升约5181.55%。这是如何做到的呢?

1. 精确的索引匹配
新索引PAWSQL_IDX1878194728完美契合查询需求:
o_orderdate作为首列,支持快速数据过滤。o_custkey和o_totalprice的组合,为窗口函数的分区和排序提供支持。
2. 避免排序操作
由于索引已经根据o_custkey和o_totalprice进行了排序,数据库可以直接利用索引顺序,省去了额外的排序步骤。
3. 覆盖索引的威力
新索引包含了查询所需的所有列,实现了“覆盖索引”。这意味着数据库可以直接从索引中获取所有数据,无需访问实际的数据页,大幅减少了I/O操作。
4. 执行计划的变化
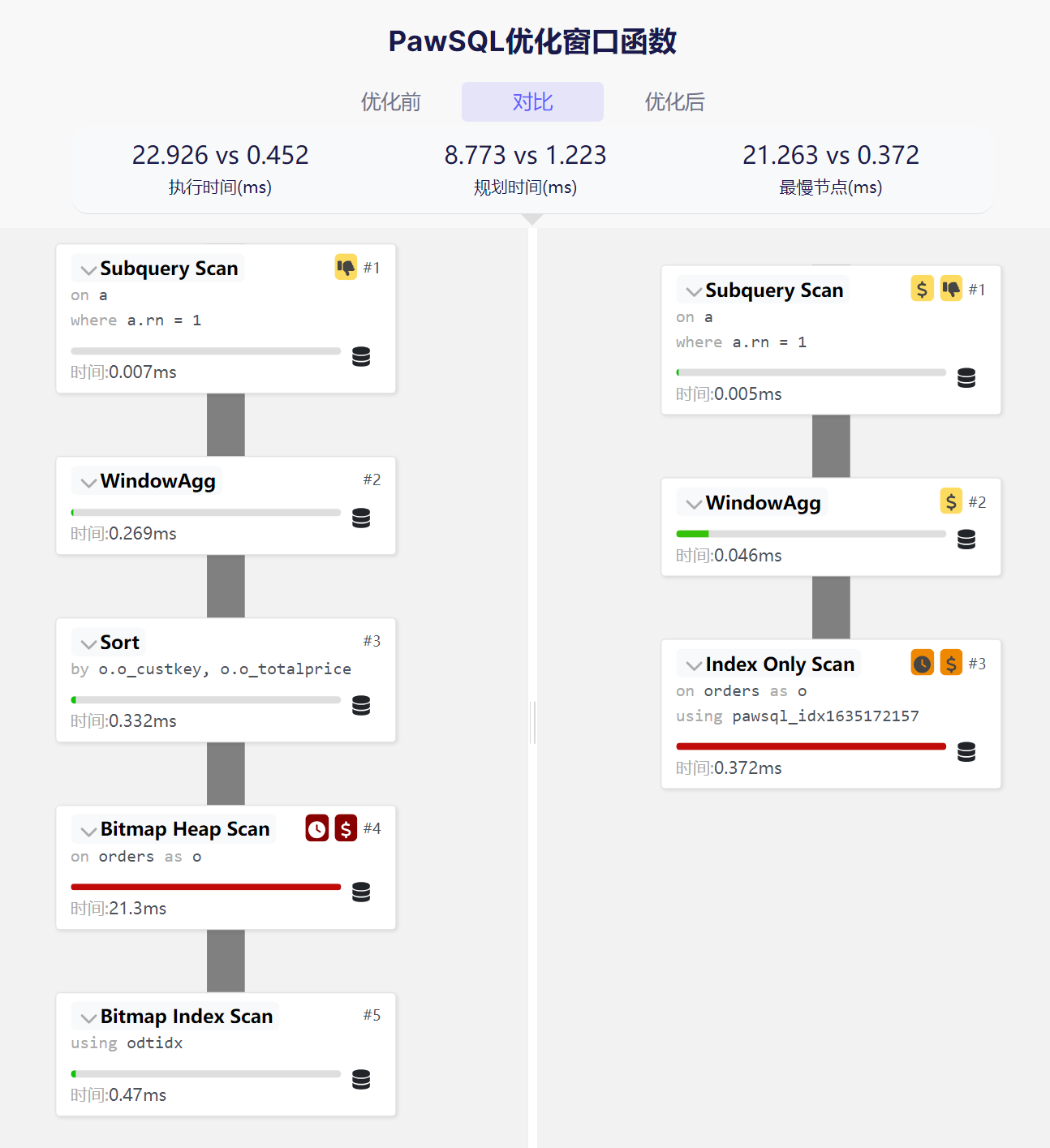
优化前:
- 使用Bitmap索引扫描和堆扫描。
- 需要额外的排序操作。
- 执行时间:22.926 ms
优化后:
- 使用索引专用扫描(Index Only Scan)。
- 无需额外排序。
- 执行时间降至0.452 ms
📚 最佳实践与注意事项
- 定期分析:利用PawSQL定期分析您的查询,尤其是那些包含窗口函数的复杂查询。
- 平衡取舍:虽然新索引提升了查询性能,但也会增加存储开销和影响写入性能。在实际应用中需要权衡。
- 删除冗余:及时清理被新索引覆盖的旧索引,如本例中的
odtidx。 - 全局视角:考虑整个应用的查询模式,不要为了优化单个查询而忽视了整体性能。
�📈 结论
PawSQL通过智能索引推荐,展示了如何大幅提升包含窗口函数的SQL查询性能。通过创建精确匹配查询需求的索引,我们可以显著减少执行时间,提高应用响应速度。在大数据时代,这种优化不仅提升了效率,还能节省宝贵的计算资源。
记住,数据库优化是一个持续的过程。定期使用像PawSQL这样的工具进行分析和优化,将帮助您的应用始终保持最佳性能状态。
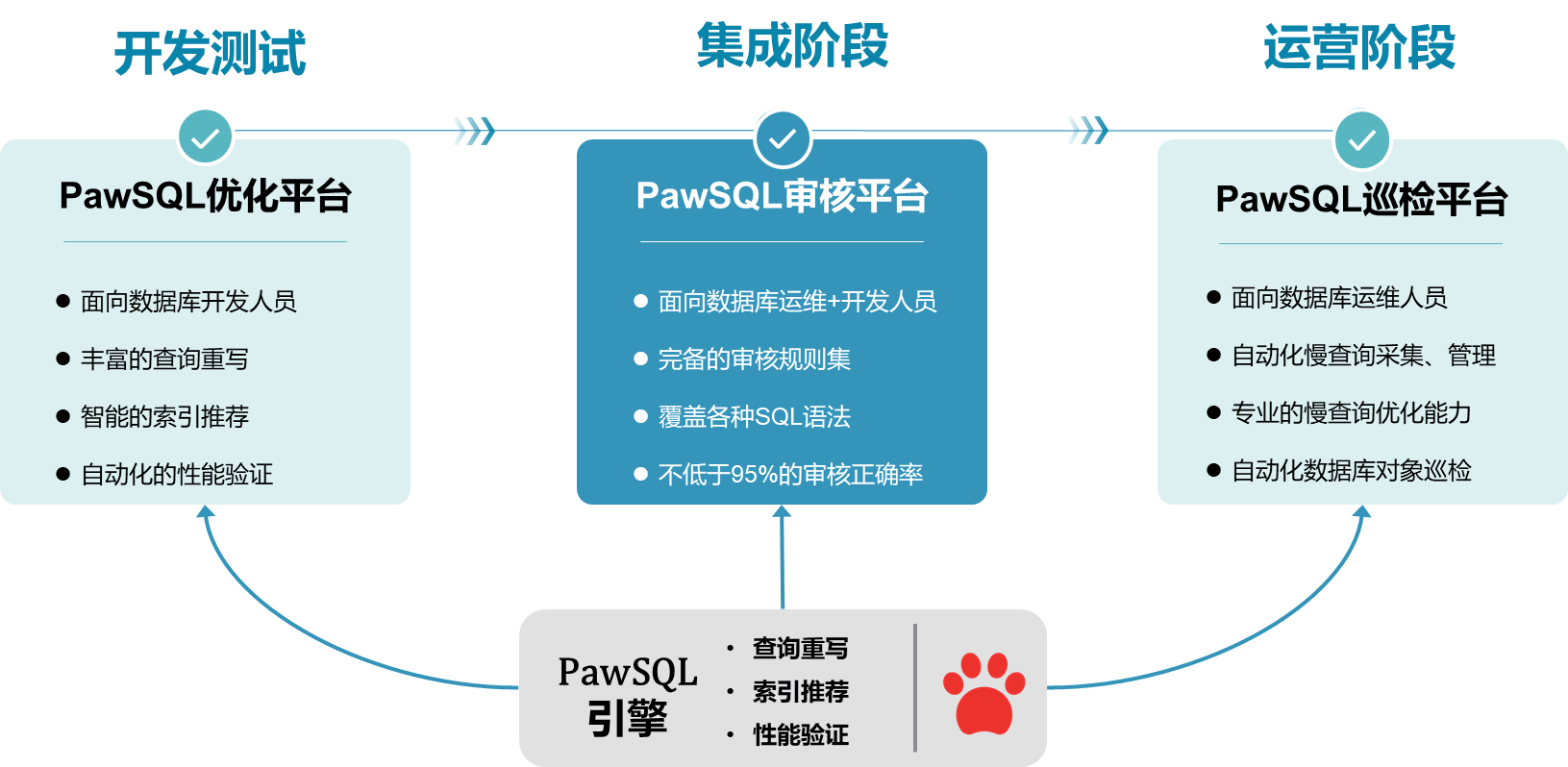
🌐关于PawSQL
PawSQL专注于数据库性能优化自动化和智能化,提供的解决方案覆盖SQL开发、测试、运维的整个流程,广泛支持MySQL、PostgreSQL、OpenGauss、Oracle等主流商用和开源数据库,以及openGauss,人大金仓、达梦等国产数据库,为开发者和企业提供一站式的创新SQL优化解决方案;有效解决了数据库SQL性能及质量问题,提升了数据库系统的稳定性、应用性能和基础设施利用率,为企业节省了大量的运维成本和时间投入。