PawSQL for TDSQL:金融级分布式数据库性能优化全攻略

在金融行业的数字化转型浪潮中�,分布式数据库凭借其高扩展性、高可用性和高性能等优势,成为金融机构构建核心业务系统的首选。TDSQL 作为腾讯云推出的分布式数据库,广泛应用于金融、互联网、政务等领域。然而,随着业务的不断增长和数据量的爆炸式增长,如何优化 TDSQL 数据库的性能,成为众多企业和开发者面临的挑战。本文将介绍 PawSQL 为 TDSQL 数据库提供的专项优化指南,助力用户充分发挥 TDSQL 数据库的性能潜力。
一、TDSQL 数据库性能优化的重要性
TDSQL 数据库在金融级应用中,面临着高并发、大数据量、高可靠性等严峻挑战。性能优化不仅关乎业务响应速度和用户体验,更直接影响到金融机构的运营效率和风险控制能力。通过优化 TDSQL 数据库,可以实现以下目标:
- 提升业务响应速度 :减少查询延迟,提高交易处理速度,为用户提供更流畅的服务体验。
- 降低运营成本 :优化资源利用率,减少硬件投入和运维成本,提高企业的经济效益。
- 增强系统稳定性 :通过合理的优化策略,提高数据库的稳定性和可靠性,降低系统故障风险。
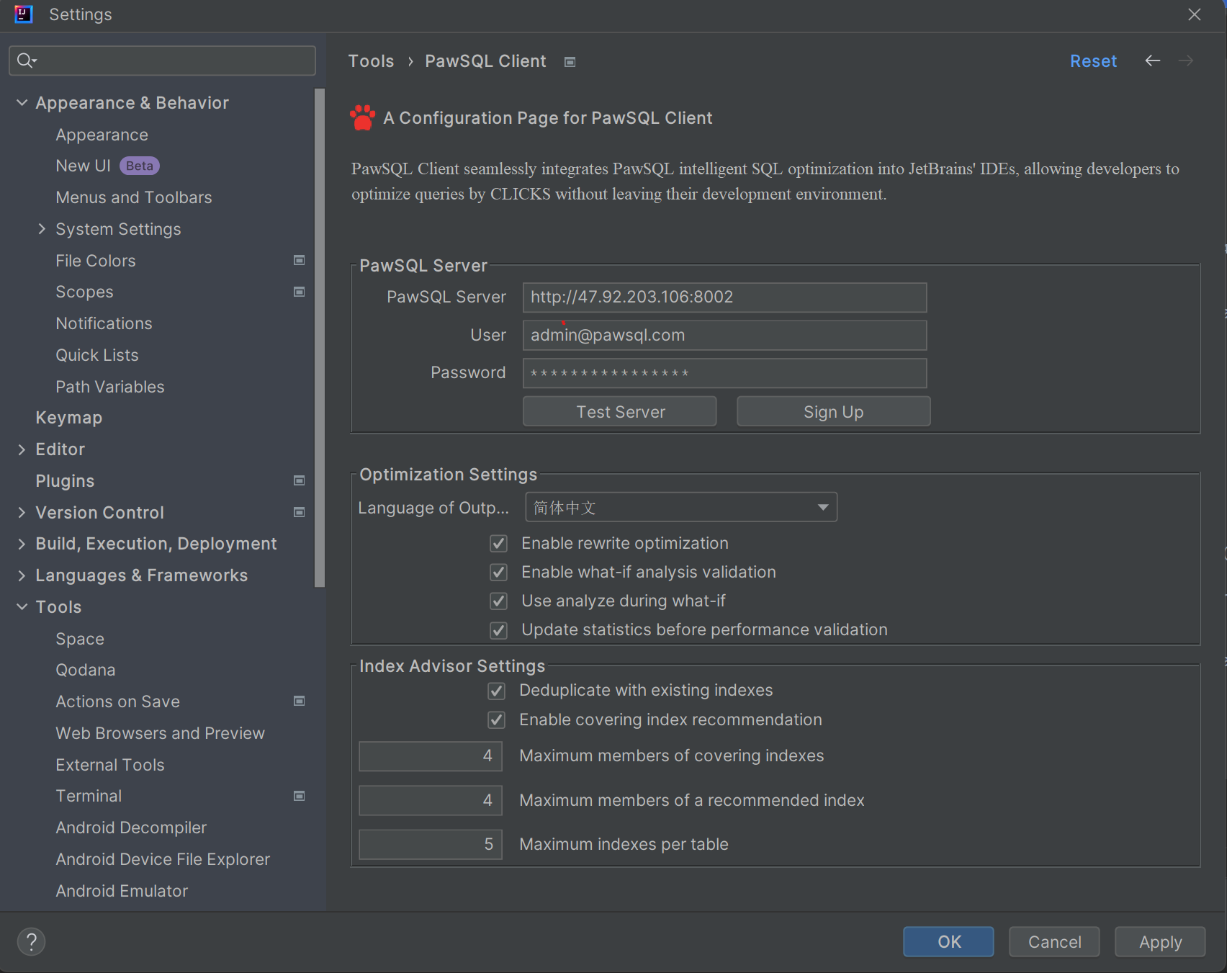
二、PawSQL for TDSQL 的专项优化能力
1.TDSQL 深度 SQL 语法支持
PawSQL 为 TDSQL 数据库提供了深度的 SQL 语法支持,帮助用户更好地利用 TDSQL 的特性进行性能优化。
- 完整支持 MySQL 语法体系 :TDSQL 基于 MySQL 开发,PawSQL 完整支持 MySQL 语法体系,确保用户在使用 PawSQL 进行 SQL 优化时,能够无缝兼容 TDSQL 的语法要求。
- 完整解析 TDSQL 特有 DDL 语法 :TDSQL 具有一些特有的 DDL 语法,如分布式表的创建、分区表的定义等。PawSQL 能够完整解析这些特有语法,为用户提供准确的 SQL 优化建议。
-- hash分片或广播表
CREATE TABLE [IF NOT EXISTS] tbl_name
[(create_definition)]
[local_table_options]
shardkey=column_name|noshardkey_allset
-- range或list分片
CREATE TABLE [IF NOT EXISTS] tbl_name
[(create_definition)]
[local_table_options]
TDSQL_DISTRIBUTED BY range|list (column_name) [partition_options]
2.优化规则体系升级
PawSQL 针对 TDSQL 数据库的分布式特性,新增了多项优化规则,帮助用户避免常见的性能问题。
- 分布式 SQL 设计规范 :
- 避免表关联字段不是分布键 :在分布式数据库中,表关联字段如果不是分布键,会导致数据跨节点传输,增加网络开销。PawSQL 提醒用户在设计表关联时,尽量使用分布键作为关联字段。
- 分布式数据库 DML 应避免表关联 :在分布式环境下,DML 操作涉及表关联时,可能会导致复杂的分布式事务处理,影响性能。PawSQL 建议用户尽量避免在 DML 操作中进行表关联。
- 分布式数据库 DML 缺少分片字段的等值条件 :在分布式数据库中,DML 操作缺少分片字段的等值条件,会导致全表扫描,严重影响性能。PawSQL 提醒用户在 DML 操作中,务必包含分片字段的等值条件。
- 分布键设计规范 :
- 分布键不建议使用多个字段 :使用多个字段作为分布键,可能会导致数据分布不均匀,增加查询复杂度。PawSQL 建议用户尽量使用单个字段作为分布键。
- 分布键应使用区分度大的字段 :分布键的区分度越大,数据分布越均匀,查询性能越好。PawSQL 提醒用户选择区分度大的字段作为分布键。
- 分布策略设计规范 :
- 大表不建议使用复制分布 :大表使用复制分布,会导致数据存储冗余,增加存储成本和网络开销。PawSQL 建议用户对大表使用 hash 分布或 range 分布。
- 分布方式建议使用 hash 分布 :hash 分布能够实现数据的均匀分布,提高查询性能。PawSQL 建议用户优先选择 hash 分布方式。
- 避免使用非分布表 :非分布表在分布式数据库中可能会导致数据集中存储,影响系统的扩展性和性能。PawSQL 提醒用户尽量避免使用非分布表。
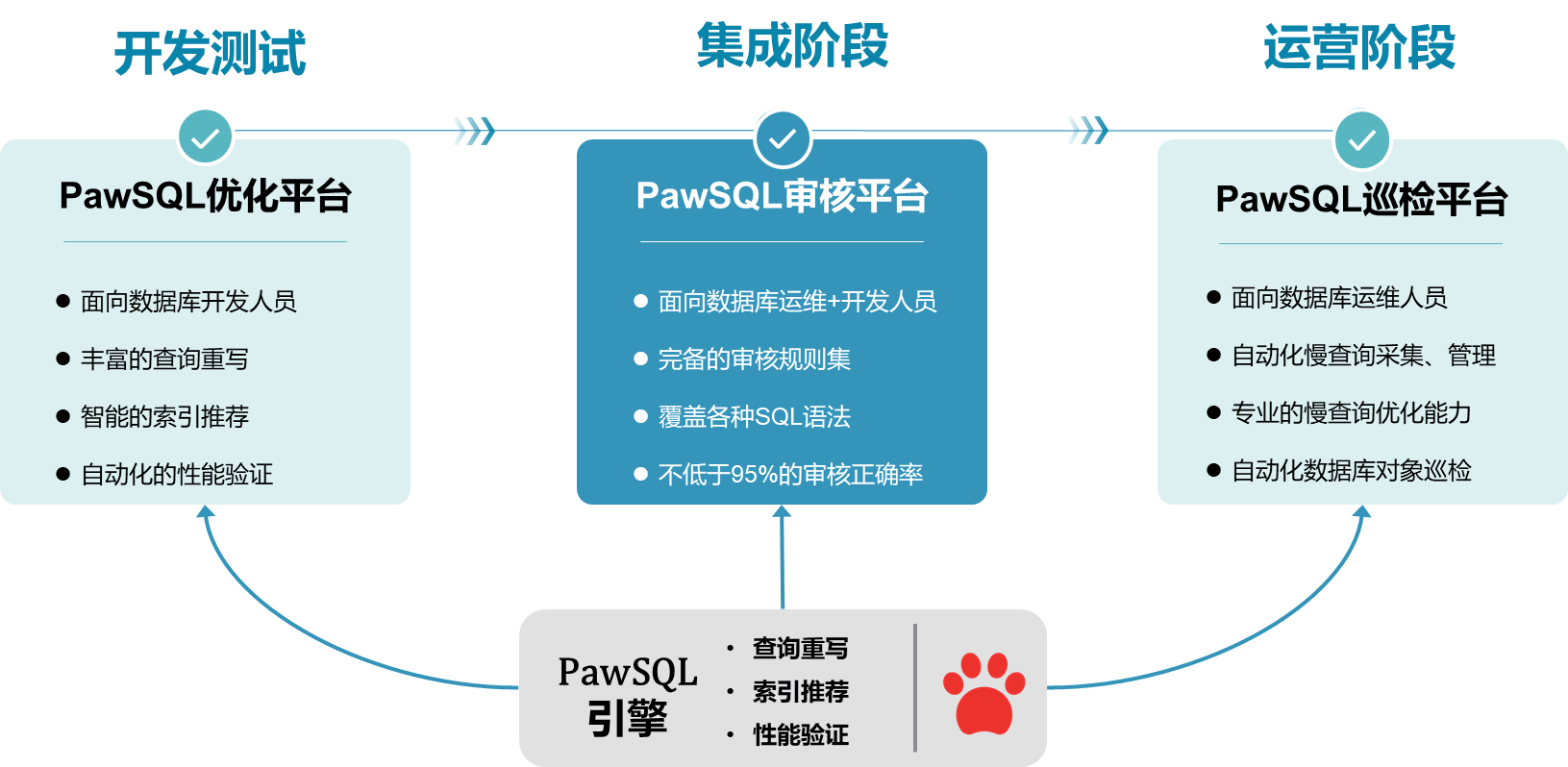
三、SQL 优化全生命周期矩阵
1.开发测试阶段:智能 SQL 优化
在开发测试阶段,PawSQL 为应用开发人员和测试人员提供了一站式的在线 SQL 优化工具。
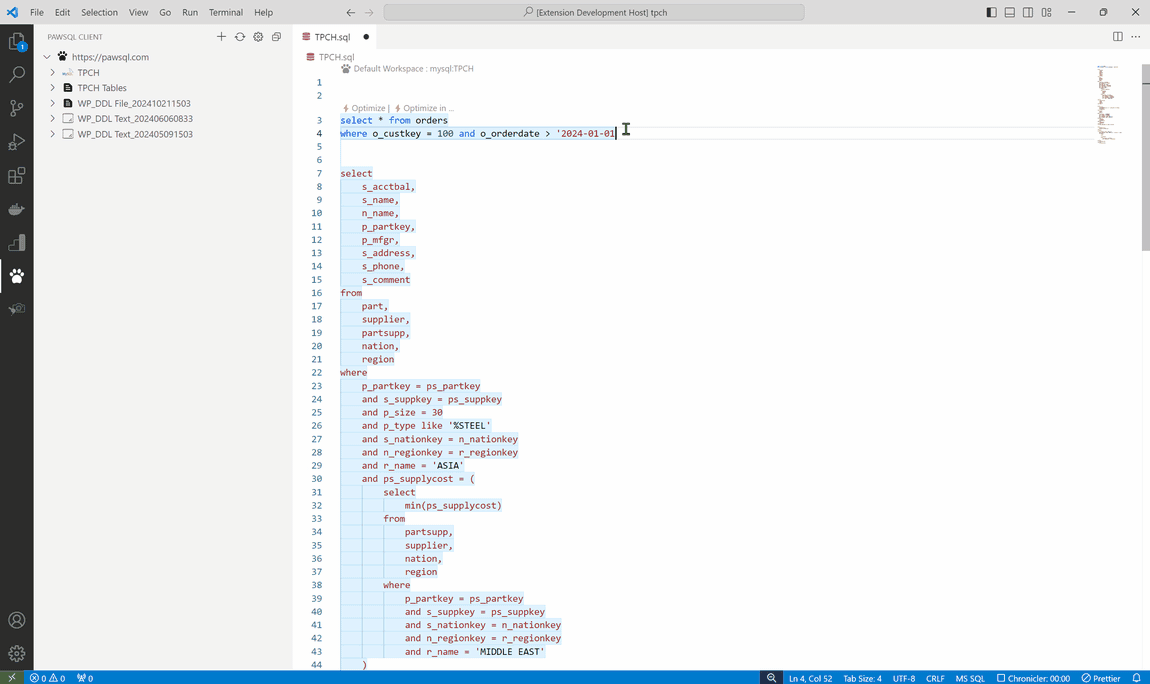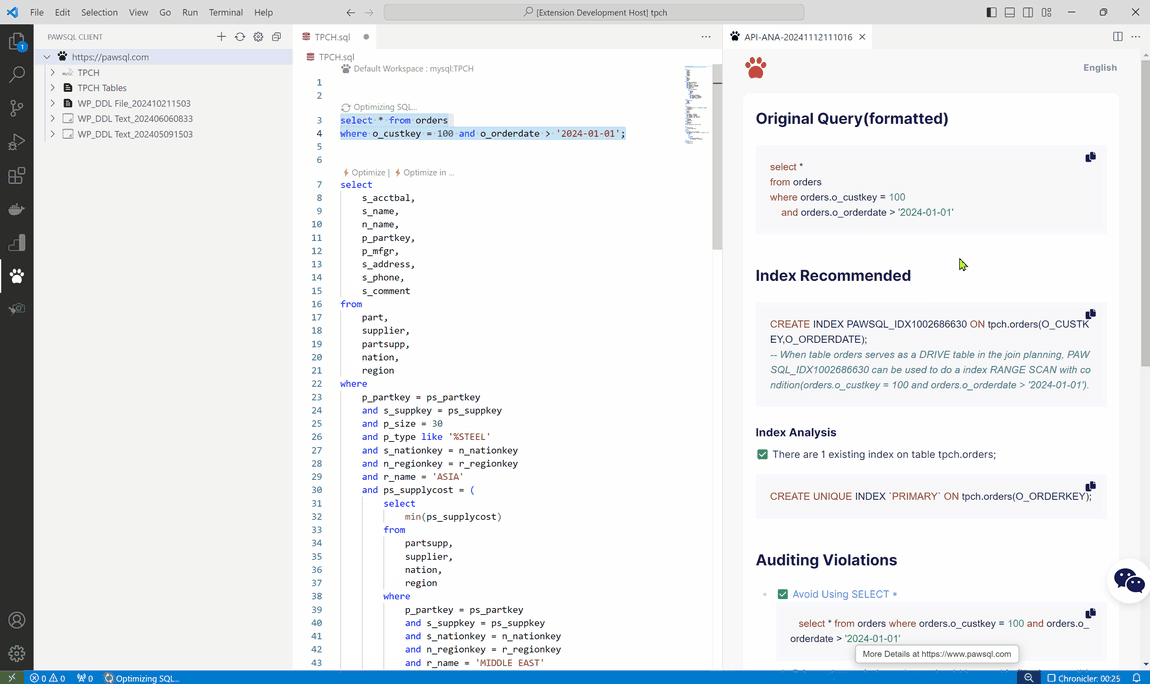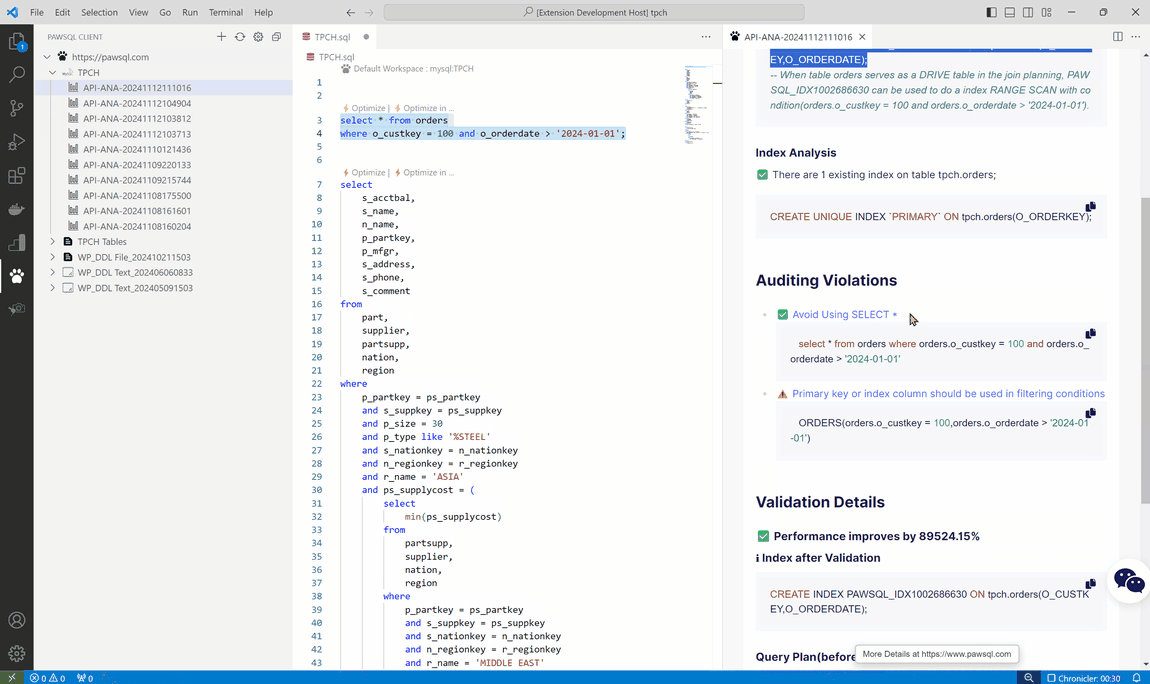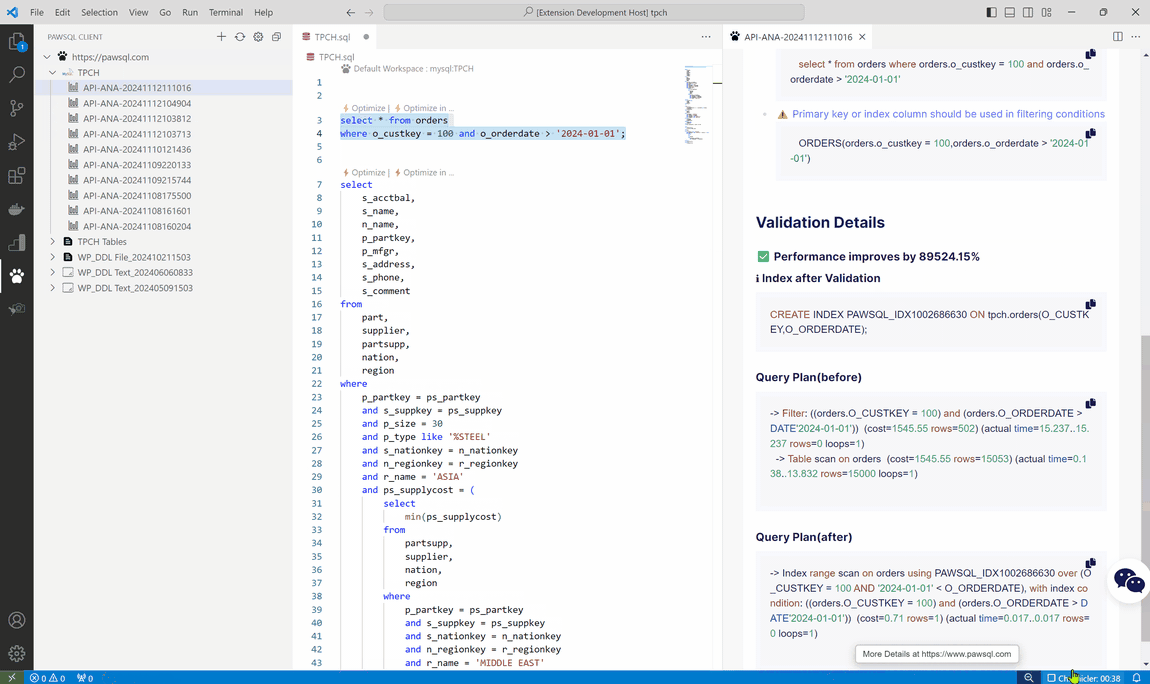
- 查询重写优化 :PawSQL 能够自动对 SQL 查询进行重写优化,如将复杂的子查询转换为更高效的连接查询,优化查询条件的顺序等,帮助用户提高查询性能。
- 智能索引推荐 :PawSQL 根据 SQL 查询的特点和数据分布情况,为用户提供智能的索引推荐。通过创建合适的索引,可以显著提高查询速度,减少数据扫描量。
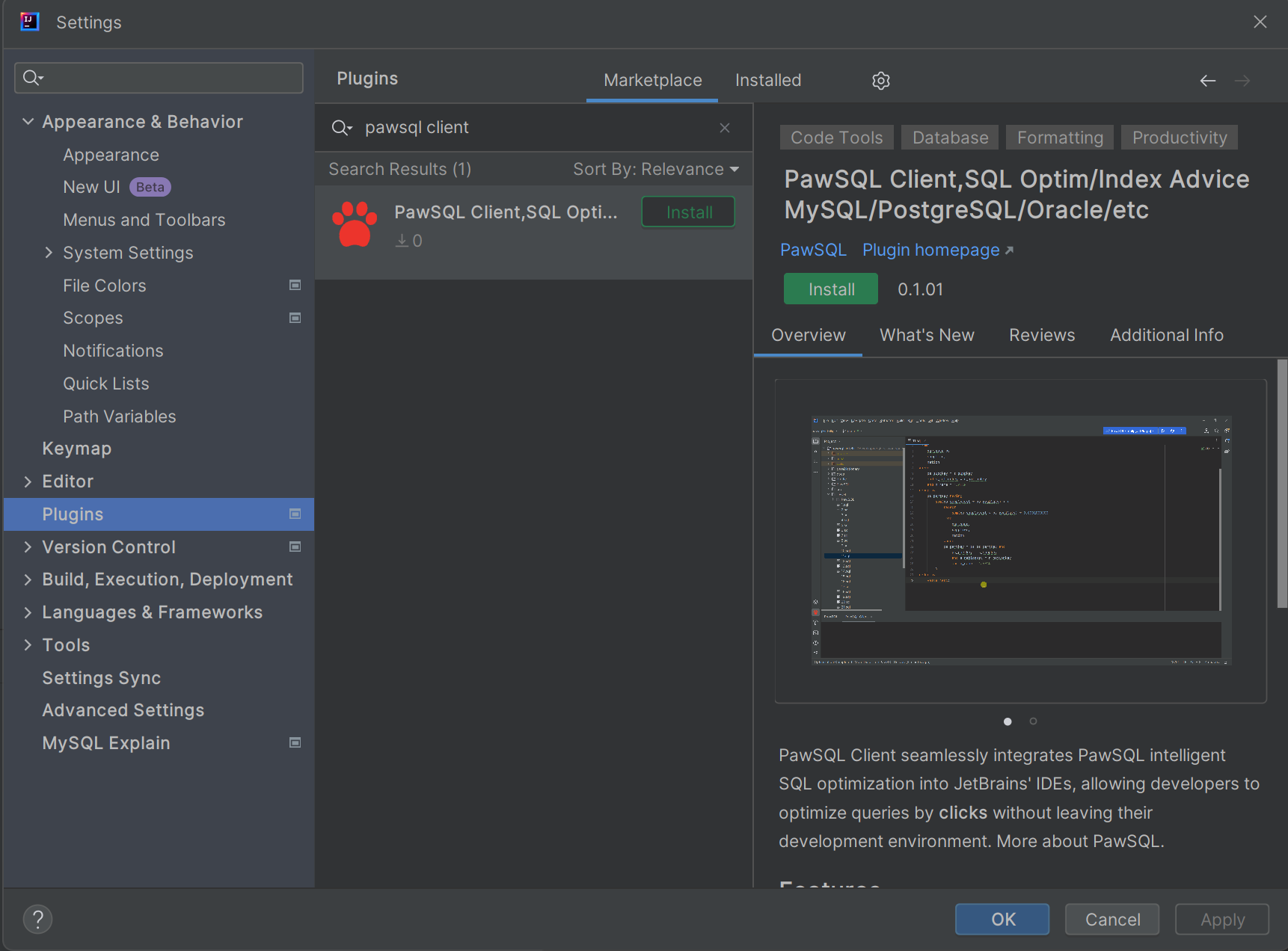
PawSQL 优化平台已经完成了和常用 IDE 的集成(VSCode 及 Jetbrains),开发人员无需��离开开发环境即可进行 SQL 优化,提高工作效率。
2.代码集成阶段:完备的 SQL 审核
在代码集成阶段,PawSQL 审核平台凭借其领先的核心技术,为 SQL 质量管理团队提供全面且精准的智能 SQL 审核能力。
- 自研 SQL 解析器 :PawSQL 的自研 SQL 解析器能够准确解析各种复杂的 SQL 语句,为后续的规则匹配和优化建议提供准确的语法信息。
- 基于语法树的规则匹配 :PawSQL 通过构建 SQL 语法树,对 SQL 语句进行深度分析,匹配各种优化规则,确保审核结果的准确性。
- 上下文信息更新 :PawSQL 能够根据 SQL 语句的上下文信息,动态更新审核结果,提供更贴合实际的优化建议。
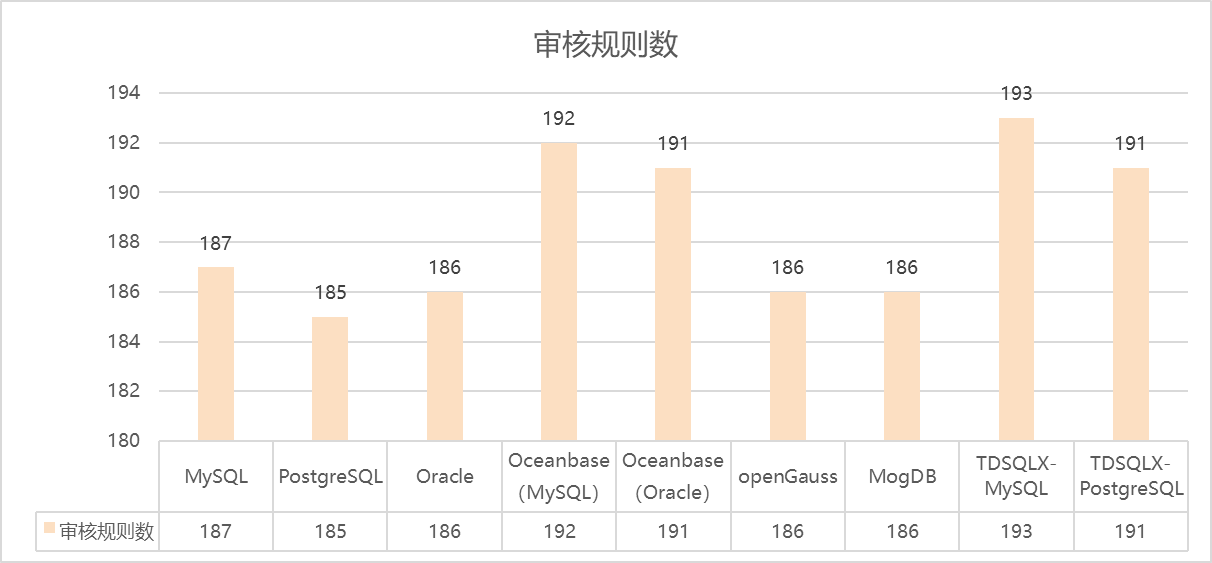
PawSQL 从语法规范、性能效率、安全性等多个维度进行全面检查,并提供针对性的优化建议,助力企业提升 SQL 性能和应用程序效率。针对 TDSQL 数据库的分布式特性,PawSQL 提供专门的分布式查询优化建议,其适用规则数据超过了 190 个。
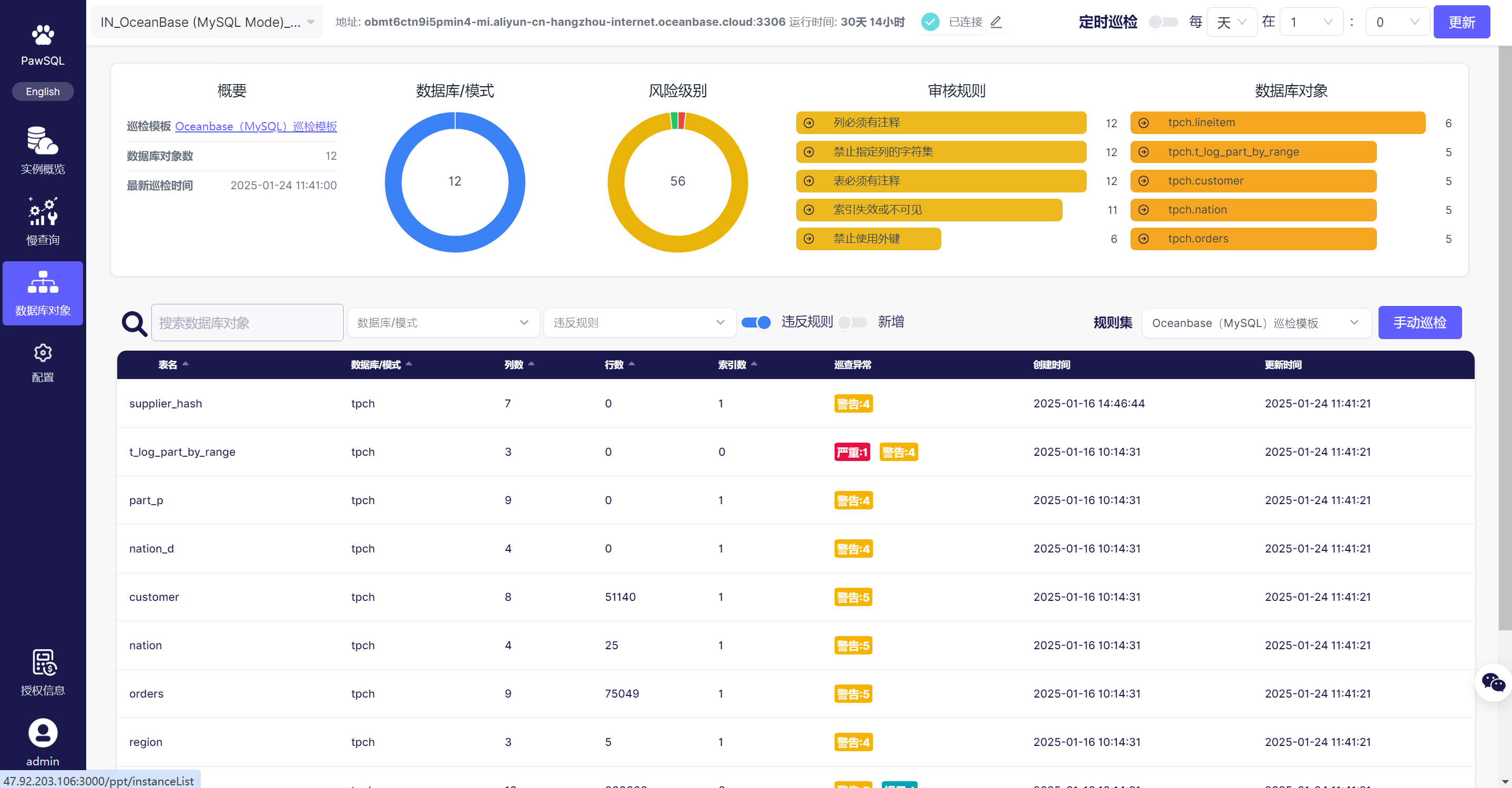
3.运维阶段:性能巡检平台
在运维阶段,PawSQL 数据库性能巡检平台能够自动定期抓取数��据库中产生的慢查询,并提供 SQL 优化建议。
- 慢查询巡检 :PawSQL 能够自动捕获数据库中的慢查询语句,分析其执行计划和性能瓶颈,为用户提供详细的优化建议。通过优化慢查询,可以显著提高数据库的整体性能。
- 数据库对象巡检 :PawSQL 还能够自动定期对数据库中的对象进行巡检,识别可能的性能、安全性、可维护性等问题隐患,并提供优化建议。例如,检查索引的使用情况、表的空间利用率等,帮助用户及时发现和解决潜在问题。
PawSQL 支持 TDSQL 数据库的慢查询巡检及数据库对象巡检,为运维人员提供全方位的性能监控和优化支持。
四、总结
PawSQL for TDSQL 数据库为用户提供了一站式的性能优化解决方案。从开发测试阶段的智能 SQL 优化,到代码集成阶段的完备 SQL 审核,再到运维阶段的性能巡检平台,PawSQL 贯穿了数据库性能优化的整个生命周期。通过使用 PawSQL,用户可以充分发挥 TDSQL 数据库的性能潜力,提升业务响应速度,降低运营成本,增强系统稳定性。
在金融级分布式数据库的应用中,性能优化是一项长期而艰巨的任务。PawSQL 将持续关注 TDSQL 数据库的发展和用户需求,不断优化和完善优化规则体系,为用户提供更优质、更高效的性能优化服务。立即体验 PawSQL,释放 TDSQL 数据库的性能潜力,为您的业务发展保驾护航!