SQL优化技巧 - 查询折叠
· 阅读需 6 分钟

Optimize your SQL Queries by Clicks!
问题定义
查询折叠(Query Folding)指的是把查询中的视图、CTE或是DT子查询展开,并与引用它的查询语句合并,从而减少查询语句的子查询数目,降低其复杂度的一种优化算法。其收益有以下三个方面:
- 避免中间结果集的物化
- 启用更多的连接顺序规划
- 提供更多的索引建议机会(PawSQL索引推荐引擎)
考虑下面的例子,
SELECT * FROM (SELECT c_custkey, c_name FROM customer) AS dt;
重写后的SQL为,
SELECT c_custkey, c_name FROM customer
注1. 在下文中,我们将使用“视图”一词,但所有描述也适用于CTE或是DT子查询。
注2. 本文所使用的执行计划可视化工具为 PawSQL Explain Visualizer , 支持MySQL、PostgreSQL、openGauss等数据库。
查询折叠的两种类型
PawSQL优化引擎针对不同的SQL语法结构,支持两种查询折叠的优化策略。其中第一种查询折叠的优化,MySQL 5.7以及PostgreSQL 14.0以上的版本都在优化器内部支持了此类优化;而第二类查询折叠的优化,在最新的MySQL及PostgreSQL版本中都没有支持。
查询折叠类型 I
适用条件
- 在视图本身中,没有distinct关键字
- 在视图中没有聚集函数或窗口函数
- 在视图本身中,没有LIMIT子句
- 在视图本身中,没有UNION或者UNION ALL
- 在外部查询块中,被折叠的视图不是外连接的一部分。
重写策略
将视图拆分并合并到外部查询块中。
案例
- 原始查询
select c.c_name, sum(o_totalprice) price
from customer c, (select o_custkey, o_totalprice from orders where o_shippriority=0)dt
where c.c_custkey = dt.o_custkey
group by c.c_name
- 原始查询的执行计划
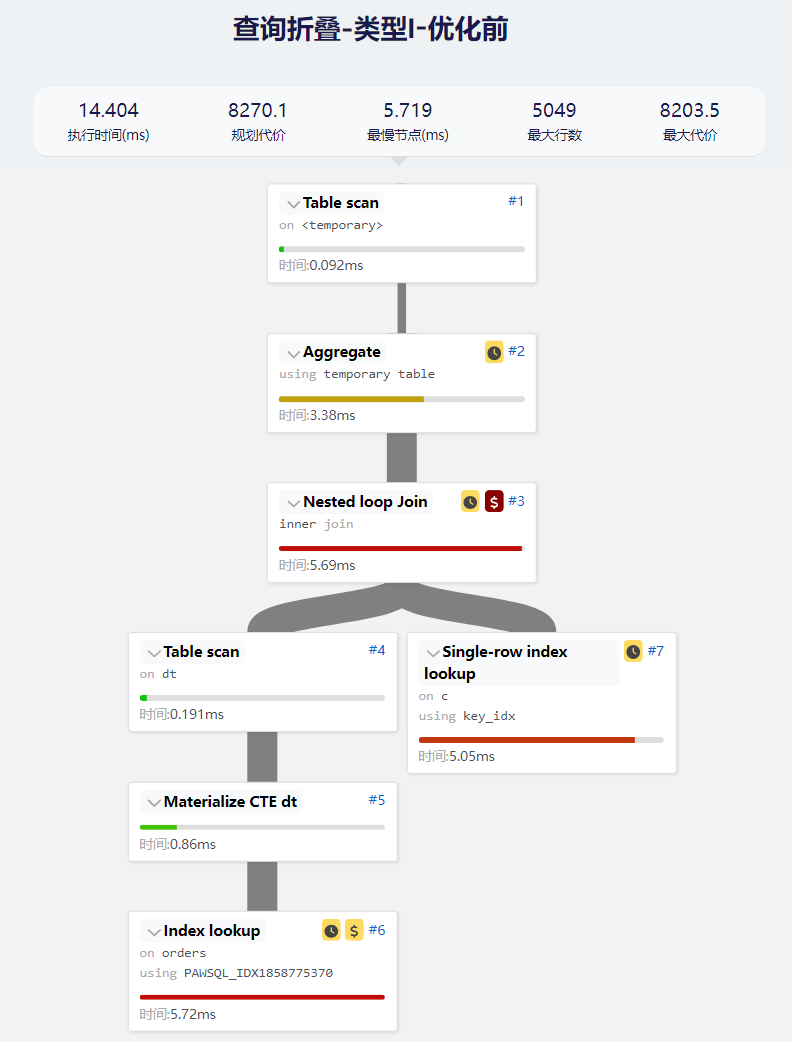
- 优化后的查询
select c.c_name, sum(o_totalprice) as price
from customer c, orders
where c.c_custkey = o_custkey and o_shippriority=0
group by c.c_name
- 优化后的查询执行计划
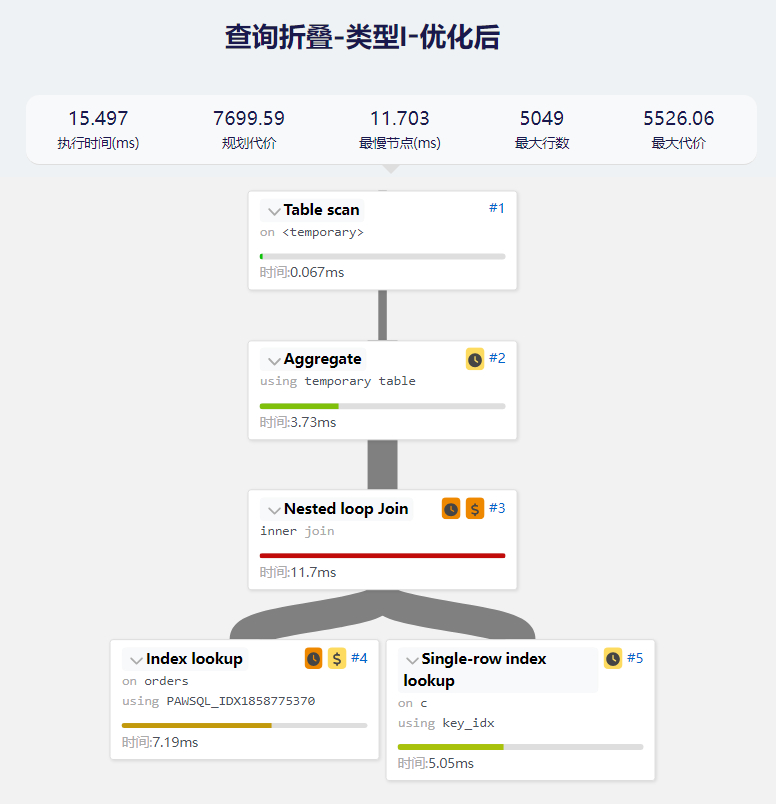
我们可以看到原始查询的执行计划中有一个物化步骤, 通过SQL重写后,消除了此物化步骤。
查询折叠类型 II
适用条件:
- 在外部查询块中,
视图是唯一的表引用 - 在外部查询块中,没有分组、聚集函数和窗口函数
- 在视图内部没有使用窗口函数
重写策略:
将外部查询合并至视图,并删除外部查询。
案例
- 原始查询
select dt.price
from (select c.c_name, sum(o_totalprice) price
from customer c, orders
where c.c_custkey = orders.o_custkey
group by c.c_name) dt
where dt.c_name like '139%';
- 原始查询执行计划
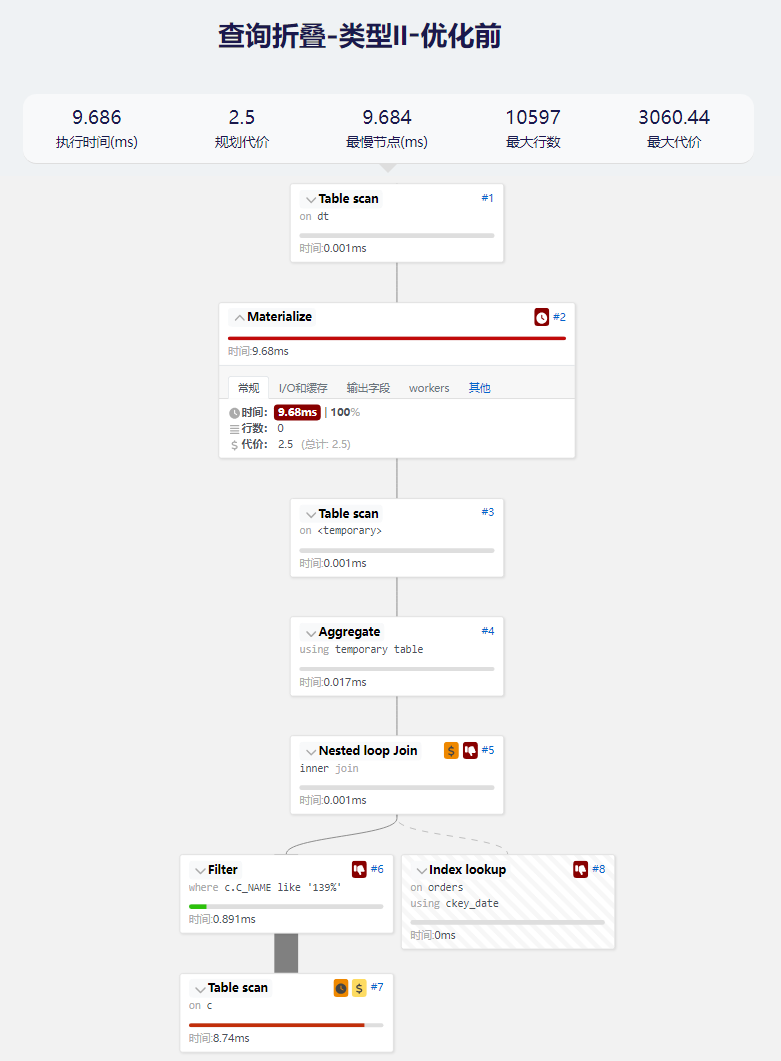
- 优化后的查询
select sum(o.O_TOTALPRICE)
from customer as c, orders o
where c.c_custkey = o.o_custkey
and c.c_name like '139%'
group by c.c_name
- 优化后的查询执行计划
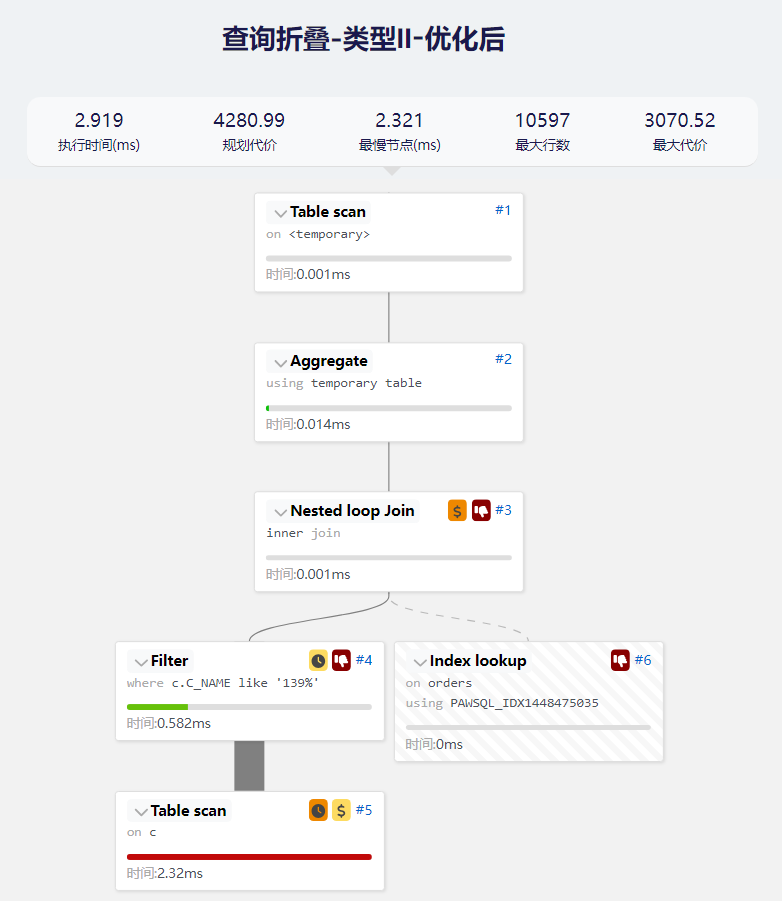
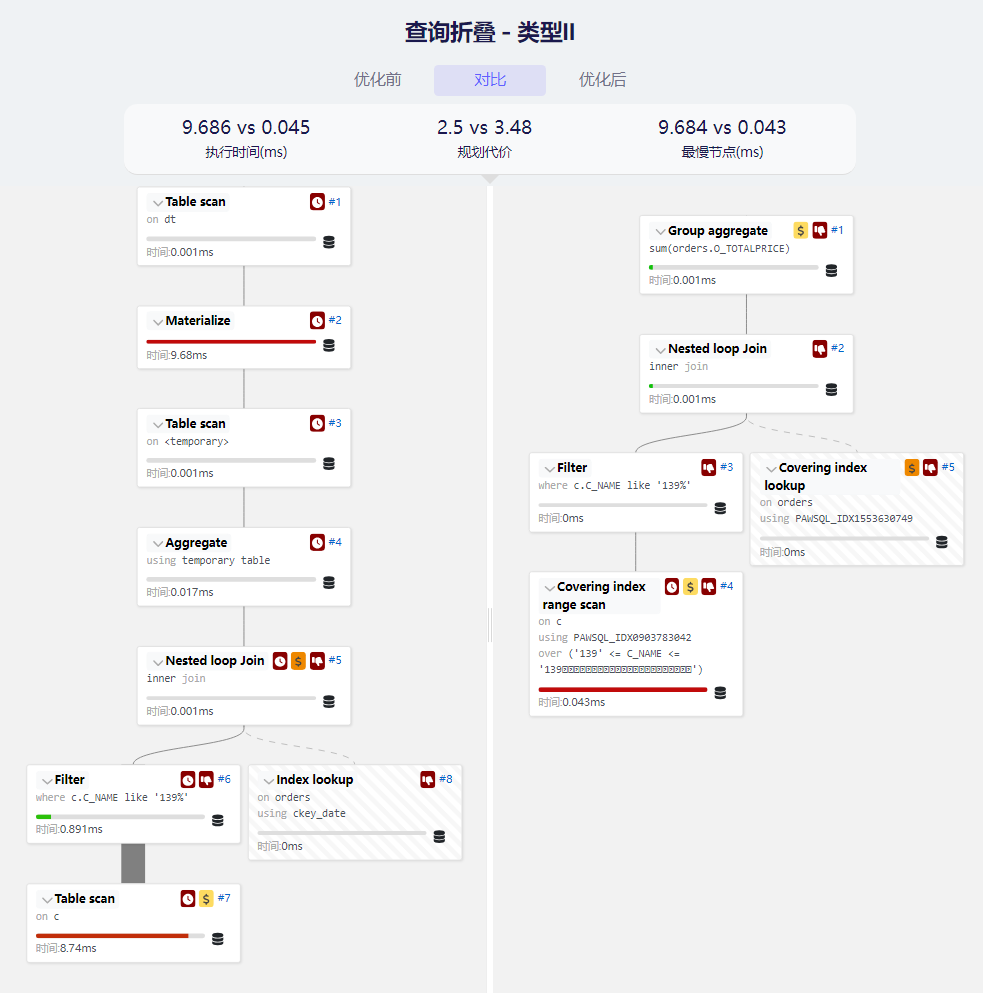
与类型1类似,我们可以看到重写优化后消除了物化步骤,同时性能提升了231.83%。
PawSQL对查询折叠优化的支持
- 自动优化:PawSQL针对所有数据库默认开启此优化,以下是案例2在PawSQL中的优化结果;可以看到,基于重写后的SQL,PawSQL进一步推荐了更高效的索引。

- 点击优化页面的执行计划对比图标,可以看到优化前后的执行计划对比
- 启用设置:用户可以在自己的默认优化设置或是定义每个优化任务的时候自主启用或禁用该选项。
关于PawSQL
PawSQL专注数据库性能优化的自动化和智能化,支持MySQL,PostgreSQL,Opengauss等,提供的SQL优化产品包括
- PawSQL Cloud,在线自动化SQL优化工具,支持SQL审查,智能查询重写、基于代价的索引推荐,适用于数据库管理员及数据应用开发人员,
- PawSQL Advisor,IntelliJ 插件, 适用于数据应用开发人员,可以IDEA/DataGrip应用市场通过名称搜索“PawSQL Advisor”安装。
- PawSQL Engine, 是PawSQL系列产品的后端优化引擎,可以以docker镜像的方式独立安装部署,并通过http/json的接口提供SQL优化服务。
联系我们
Twitter: https://twitter.com/pawsql
扫描关注PawSQL公众号