Downloads Exceed 10,000! PawSQL Advisor: How a Domestic SQL Optimization Tool Broke Through Difficulties

PawSQL Advisor, as a SQL optimization tool originated from China, recently surpassed 10,000 downloads in the JetBrains marketplace. However, behind this achievement lies a difficult journey overcoming technical, market, and user habit challenges. This article shares the obstacles faced and breakthrough strategies, demonstrating the resilience of a localized technology product.
I. Challenges for Domestic Tools: Payment Reluctance, Trust Barriers, and Ecosystem Pressure
-
Low Payment Willingness Among Individual Users
Compared to overseas developers who are accustomed to subscription payment models, domestic individual users prefer free tools and generally show low willingness to pay. Although PawSQL Advisor provides a free SaaS version (PawSQL Cloud), the JetBrains plugin requires payment, directly limiting the conversion rate of individual users. The payment habits in the domestic market force it to rely on enterprise-level private deployments as the main revenue source. -
Technical Trust and User Education Challenges
As an emerging tool, users have doubts about the accuracy of automated optimization suggestions. For example, performance verification requires connection to real databases, which may raise concerns about resource consumption in production environments. Complex index recommendation logic also requires users to have certain database knowledge to understand. How to make developers trust the "black box" optimization capabilities of the tool became a core barrier to initial promotion. -
Ecosystem Adaptation and Domestic Compatibility Challenges
Facing complex technical ecosystems of domestic databases (such as Dameng, Kingbase), PawSQL needs to invest substantial resources to adapt SQL parsers for different dialects and ensure optimization rule compatibility. Additionally, domestic enterprises' strict requirements for "independent control" also increase product certification and compliance costs.
II. Breakthrough Strategies: Technical Differentiation, Scenario Focus, and Ecosystem Integration
Despite numerous difficulties, PawSQL Advisor has achieved counter-trend growth through a "technology + scenario" dual-drive approach:
-
Building Technical Closed Loop for Competitive Advantage
Compared to competitors like EverSQL, PawSQL Advisor not only provides index recommendations but also integrates performance verification and execution plan visualization functions, addressing the trust issue of "whether optimization suggestions are effective." With over 190 built-in optimization rules covering complex scenarios such as HAVING condition push-down and window function optimization, plus intelligent index recommendation capabilities, it forms a powerful technical moat. -
Layered Strategy Covering All User Scenarios
- Individual Users: Lowering the usage threshold through a free SaaS version, guiding users to experience before converting to paid plugin users.
- Enterprise Users: Providing privately deployed PawSQL Engine, supporting integration with CI/CD processes, meeting the high data security requirements of industries such as finance and telecommunications.
- Domestic Adaptation: Deep support for domestic databases like Dameng and Kingbase, becoming one of the few performance optimization solutions in the domestic innovation field.
-
Ecosystem Integration Enhancing Developer Stickiness
As a JetBrains plugin, PawSQL Advisor seamlessly embeds into mainstream tools like IDEA and DataGrip, supporting one-click optimization of selected SQL or batch processing of files. Additionally, the VSCode plugin extends the user base, forming cross-platform coverage. This "tool as workflow" design significantly reduces user learning costs.
III. User Recognition: Efficiency Revolution in Real Scenarios
Users' active choices are the best validation of product value:
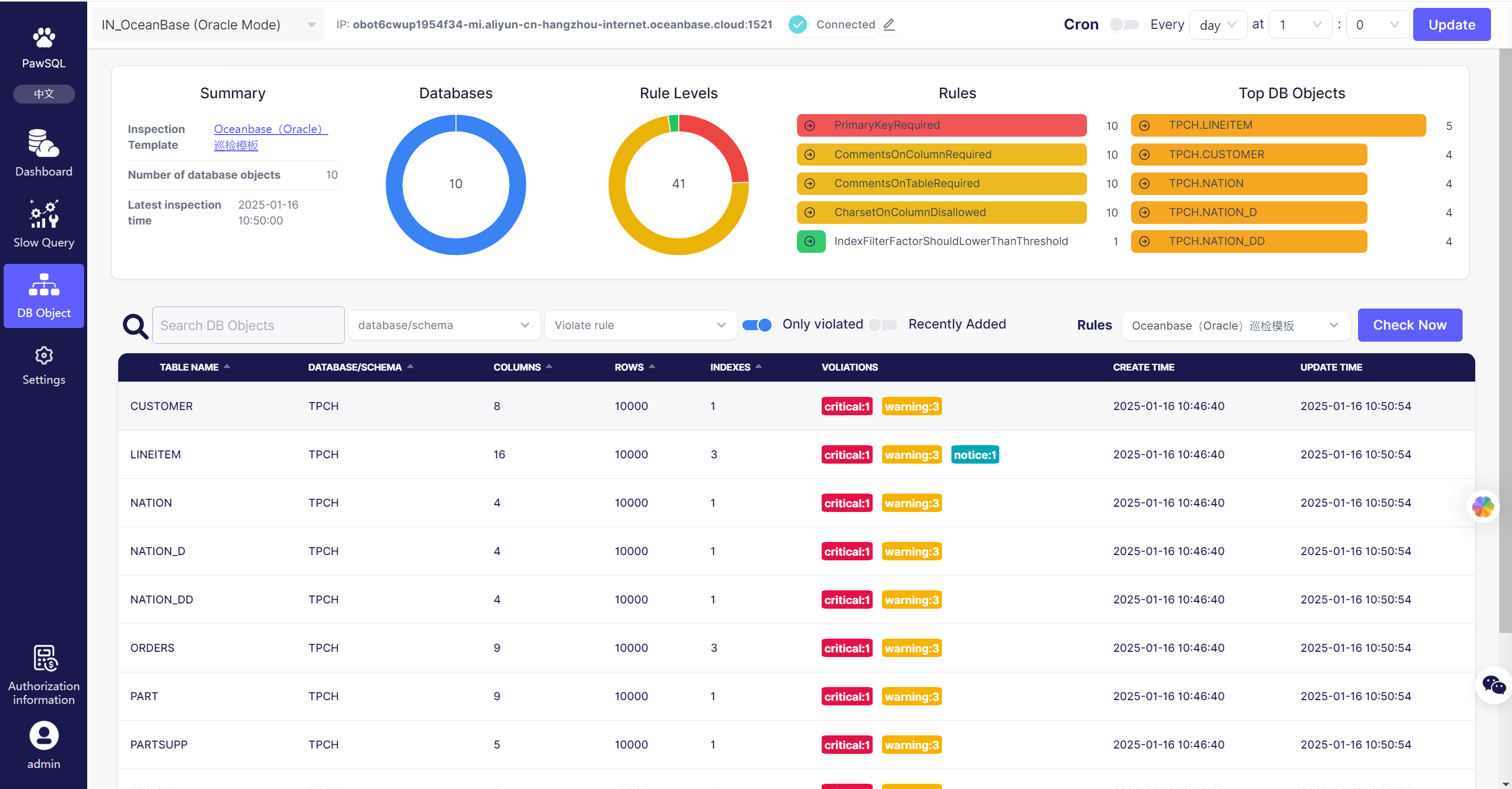
- Financial Industry Case: A bank optimized OceanBase database through PawSQL, compressing complex queries from minute-level to second-level response times, reducing hardware resource usage by 30%.
- Developer Community Feedback: Automated rules (such as avoiding
SELECT *and implicit type conversion optimization) help teams reduce code review workload by 50%. - Technical Reputation: In Zhihu's SQL optimization challenge, its automatic optimization capabilities even surpassed human experts, with performance improvement effects generating discussion in technical circles.
IV. Future Challenges: Continuous Innovation and Ecosystem Expansion
-
Exploration of AI Technology Integration
The team is attempting to incorporate large language models (such as DeepSeek) into SQL parsing and optimization suggestion generation to address more complex query scenarios. However, balancing AI "creativity" with optimization rule "certainty" still requires technological breakthroughs. -
Deep Binding with Domestic Ecosystem
With the advancement of domestic innovation policies, PawSQL needs to further adapt to more domestic databases and strive to enter government and state-owned enterprise procurement lists. This requires the product to reach higher standards in compatibility and security. -
Global Market Exploration
Although focusing on the domestic market, overseas downloads of the JetBrains plugin account for over 30%. The team plans to launch multilingual versions and explore emerging markets such as Southeast Asia and Europe to diversify single market risk.
Conclusion
PawSQL Advisor's 10,000 downloads represent not only a breakthrough in numbers but also a dual victory in technical confidence and market strategy for domestic tools. It proves that even when facing "inherent disadvantages" such as payment habits and ecosystem barriers, through precise positioning, technical depth, and ecosystem integration, local products can still occupy a place in niche fields. In the future, with the advancement of AI and domestic innovation trends, PawSQL may become another benchmark for Chinese technology going global.
Try Now: Visit the JetBrains Marketplace to install the plugin, or go to the official website for enterprise-level solutions.