PawSQL for 达梦/KES:国产数据库全方位性能优化解决方案

0. 概述
在国内信创的大背景下,金仓数据库KingbaseES和达梦数据库作为国内领先的自主可控数据库管理系统,在政府、金融、电信等关键领域扮演着举足轻重的角色。随着数据量的激增和业务复杂度的提升,国产数据库的SQL查询成为了确保业务流畅运行的关键。PawSQL,作为一款专业的数据库性能优化工具,覆盖SQL开发、测试、运维的整个流程,为金仓KingbaseES和达梦数据库提供了全面的优化支持,助力用户充分释放数据库的性能潜力。
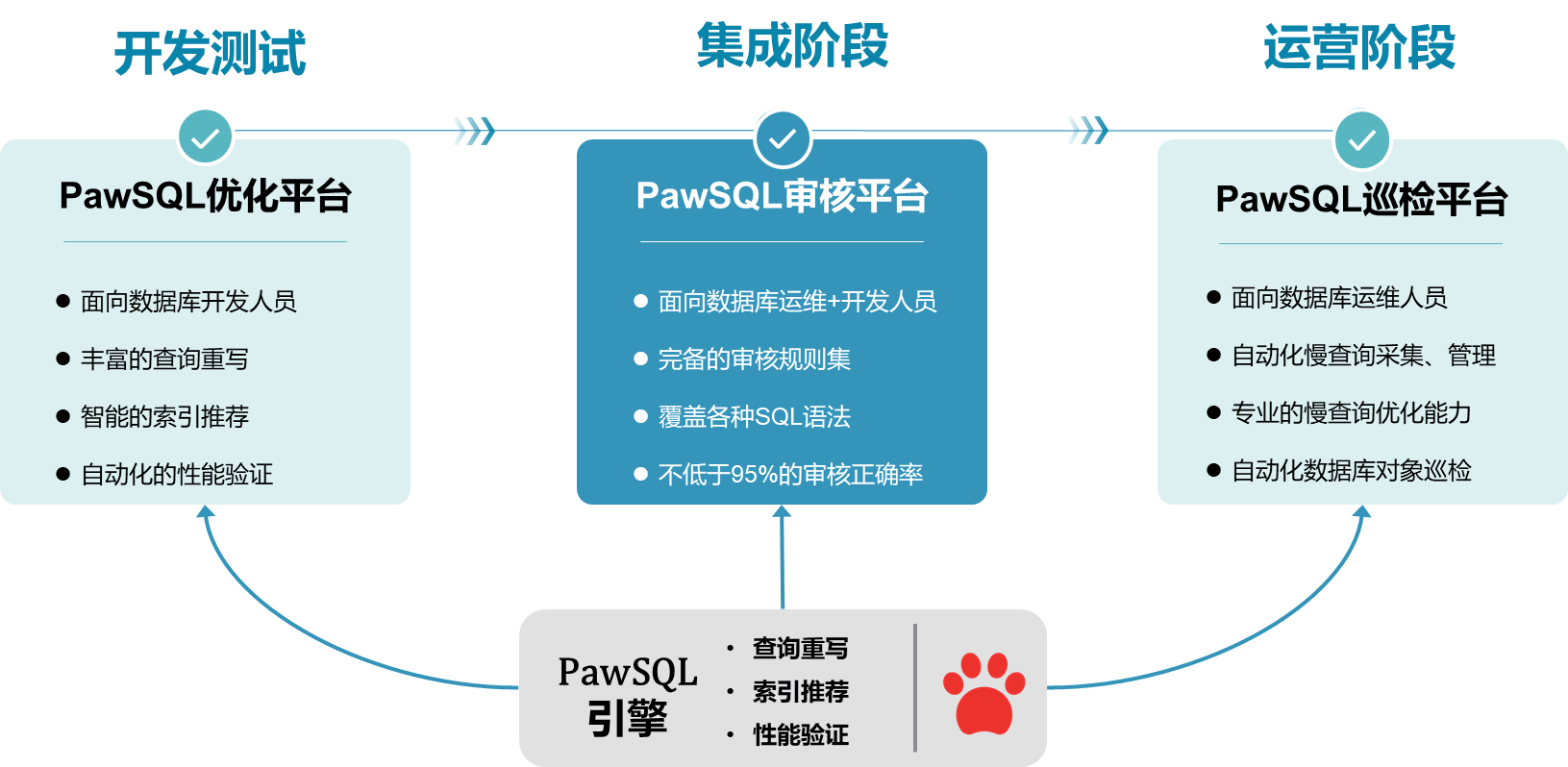
1. 纳管数据库
工作空间是SQL优化的工作环境,PawSQL支持两种方式为金仓KES/达梦数据库创建SQL优化任务的工作空间:
离线 - DDL解析:通过解析数据库的DDL文件,构建工作空间。
在线 - 元数据获取:直接从KingbaseES 数据库中获取元数据,快速建立工作空间。
2. 可配置的SQL审查
PawSQL为金仓KES/达梦数据库的应用开发人员提供智能SQL审核功能,确保代码的准确性、效率、可读性、可维护性和安全性。
3. 丰富的查询重写优化
PawSQL提�供基于启发式规则和基于代价的SQL重写优化算法,为KingbaseES 推荐语义上等价但性能更优的SQL。同时,提供重写前后的SQL文本对比,并高亮显示重写部分。
4. 智能索引推荐
PawSQL的智能索引推荐引擎为KingbaseES 上的应用查询提供最优索引策略,以适应各种SQL语法需求,显著提升查询效率。
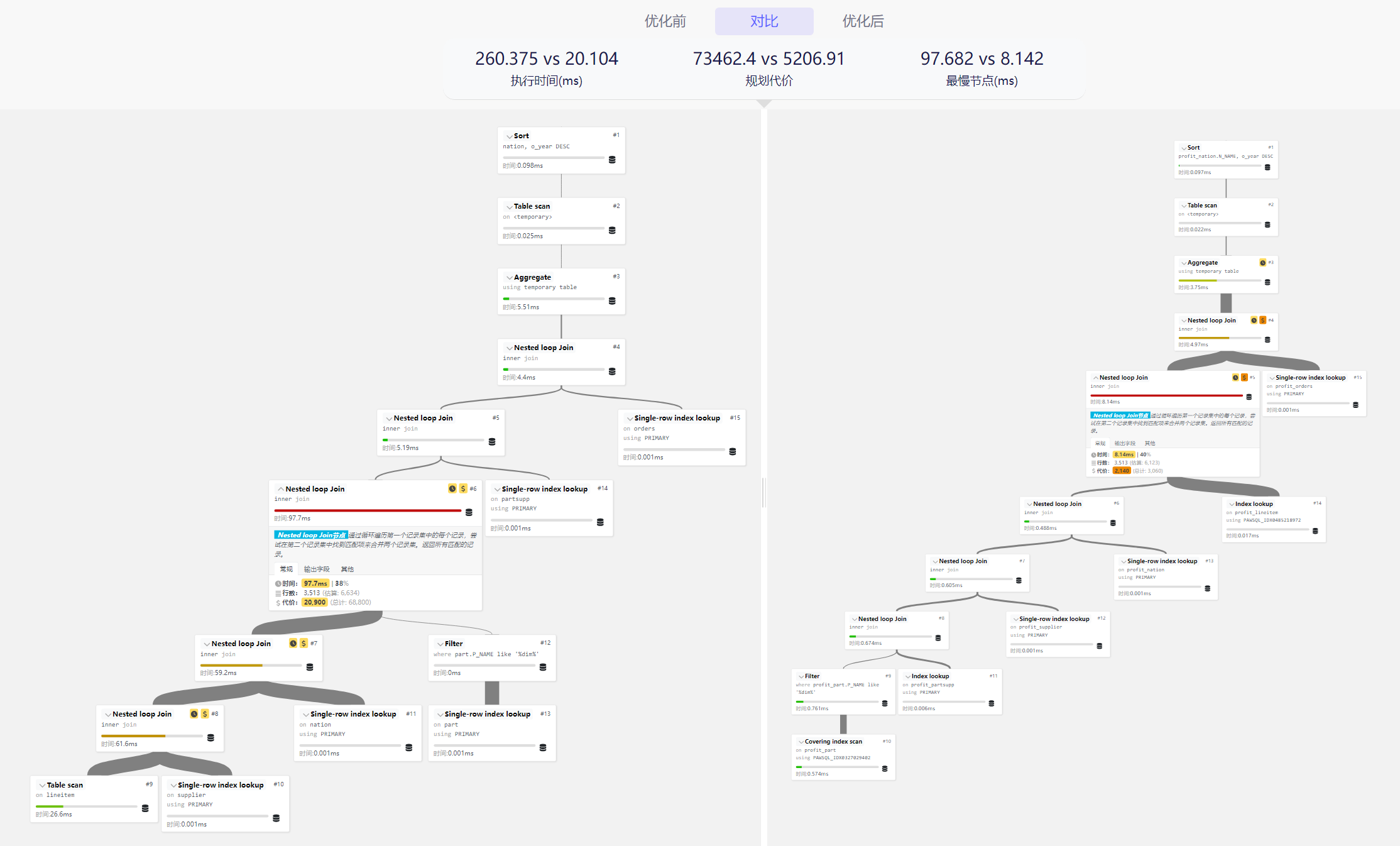
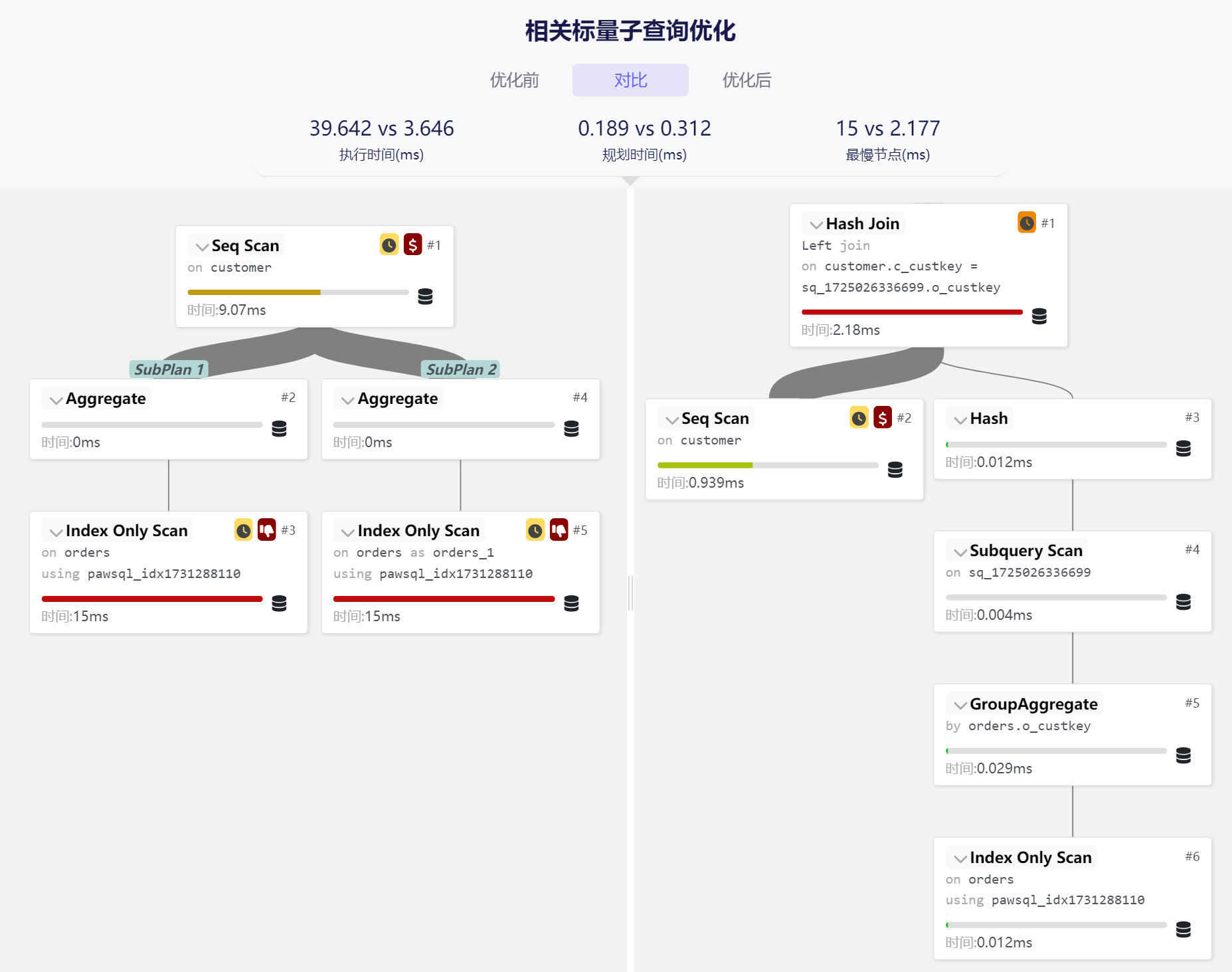
5. 执行计划可视化(PPV)
PawSQL的执行计划可视化工具(PawSQL Plan Visualizer)支持对KingbaseES 的执行计划进行图示化展示和分析,帮助用户轻松理解查询的执行过程,快速定位性能瓶颈。
6. 性能验证
PawSQL自动采集SQL优化前后的KingbaseES 数据库的执行计划,获取优化前后的执行代价,确保推荐的优化建议能够真实提升数据库性能。
7. 慢查询自动采集和管理
PawSQL性能巡检平台支持对KingbaseES 的慢查询进行采集和管理,支持基于crontab的定时采集和手工采集。
8. 数据库对象巡检
PawSQL性能巡检平台支持对KingbaseES V8的数据库对象进行定时或手动巡检,覆盖表、列、字符集、索引、约束等各种数据库对象,以识别潜在的安全、性能等潜在问题,并给出警示。
🌟 总结
PawSQL for KingbaseES,金仓数据库的全方位SQL优化解决方案,无论是日常查询还是复杂数据处理,PawSQL都以专业、高效的解决方案,助力您的数据库性能提升。
🌐 关于PawSQL
PawSQL专注于数据库性能优化自动化和智能化,提供的解决方案覆盖SQL开发、测试、运维的整个流程,广泛支持包括KingbaseES 在内的多种主流商用和开源数据库,为开发者和企业提供一站式的创新SQL优化解决方案。有效解决了数据库SQL性能及质量问题,提升了数据库系统的稳定性、应用性能和基础设施利用率,为企业节省了大量的运维成本和时间投入。