How Does PawSQL Optimize Correlated Scalar Subqueries?

In the field of data analysis, correlated scalar subqueries are undoubtedly a double-edged sword: they are powerful, capable of solving many complex problems, while simultaneously presenting significant challenges to database optimizers. Currently, only commercial database giants like Oracle have achieved relatively outstanding performance in this area. Among domestic databases, only PolarDB provides some support for correlated subqueries. This article will not only introduce how PawSQL performs cost-based rewriting optimization for correlated scalar subqueries but also demonstrate how PawSQL identifies and merges multiple similar scalar subqueries in a query to further improve scalar subquery optimization performance. With PawSQL, you can experience Oracle-like rewriting optimization capabilities on databases like MySQL and PostgreSQL.
*## 🌟 Introduction to Correlated Scalar Subqueries
In the world of SQL, correlated scalar subqueries are a powerful tool that allows subqueries to depend on column values from the outer query. This is in stark contrast to non-correlated scalar subqueries that are independent of the outer query. Correlated scalar subqueries calculate results for each row by referencing columns from the outer query.
Example:
SELECT employee_name
FROM employees e
WHERE salary > (SELECT AVG(salary)
FROM employees
WHERE department_id = e.department_id);
In this example, the subquery calculates the average salary for each department and compares it with the salary in the main query, demonstrating the powerful functionality of correlated scalar subqueries.
🏎️ Challenges and Opportunities: From an Optimizer's Perspective
Although correlated scalar subqueries are powerful, they present significant challenges to database optimizers:
- Repeated Calculations: On large datasets, subqueries may be recalculated repeatedly, impacting performance.
- High Computational Overhead: Complex calculations, such as aggregate functions, can lead to query performance degradation.
- Query Rewriting Difficulties: Transforming scalar subqueries into join operations or other forms is not always easy.
- Data Dependency: Optimization effectiveness depends on data distribution and table structure, requiring flexible optimizer responses.
For correlated scalar subqueries, while de-correlation does not always perform better than correlated subqueries, cost-based rewriting optimization strategies offer a new perspective. Currently, only a few databases like Oracle and PolarDB have implemented these advanced optimization techniques.
🚀 PawSQL: A New Realm of Correlated Scalar Subquery Optimization
PawSQL optimizes correlated scalar subqueries through:
- Cost-Based Rewriting: Supporting de-correlation of scalar subqueries in conditions and select columns.
- Merge Rewriting: Optimizing multiple structurally similar scalar subqueries.
🎯 Case Study
Original Query: The original query used two correlated subqueries, calculating the total order price and order count for each customer on a specific date. This structure is typically inefficient, as it requires repeated execution of two subqueries for each customer.
SELECT c_custkey,
(SELECT SUM(o_totalprice)
FROM ORDERS
WHERE o_custkey = c_custkey AND o_orderdate = '2020-04-16') AS total,
(SELECT COUNT(*)
FROM ORDERS
WHERE o_custkey = c_custkey AND o_orderdate = '2020-04-16') AS cnt
FROM CUSTOMER
Rewritten Query: PawSQL's optimization engine merges the two correlated subqueries into a derived table, then associates it with the main query through a left outer join.
SELECT c_custkey, SUM_ AS total, count_ AS cnt
FROM CUSTOMER LEFT OUTER JOIN (
SELECT o_custkey, SUM(o_totalprice) AS SUM_, COUNT(*) AS count_
FROM ORDERS
WHERE o_orderdate = '2020-04-16'
GROUP BY o_custkey) AS SQ ON o_custkey = c_custkey
Performance Improvement: After optimization, performance is expected to improve by 1,131.26%, a significant enhancement!
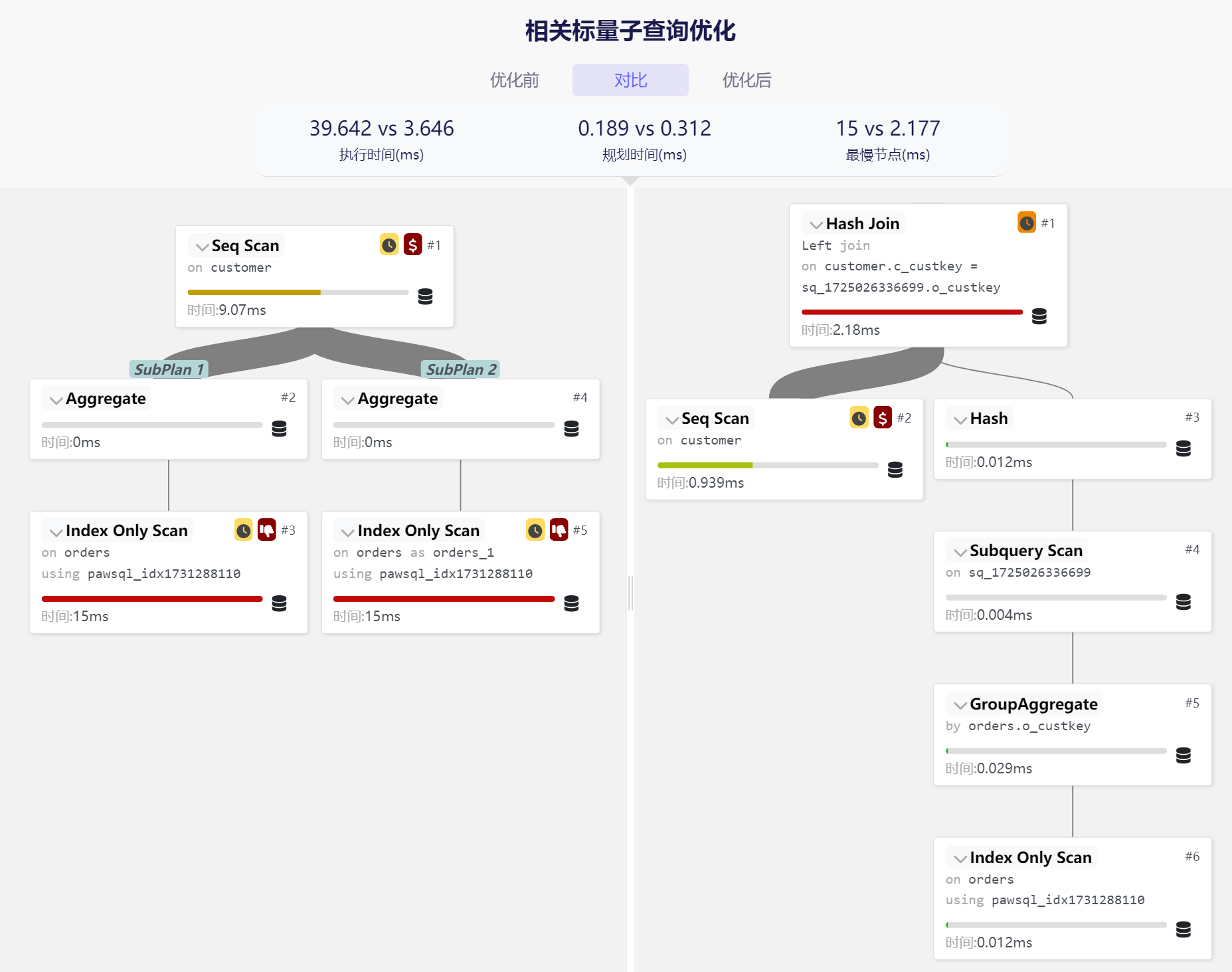
Execution Plan Improvements:
- Preliminary aggregation of orders table data significantly reduces the volume of data to be processed
- Eliminates repeated subquery executions by merging two subqueries into one
- Uses hash join to efficiently associate customer and aggregated orders data
This optimization case demonstrates the effectiveness of PawSQL's correlated scalar subquery rewriting technique. By merging multiple correlated subqueries into a single derived table and using an outer join, the optimizer can significantly reduce redundant calculations and data access.
🌐 About PawSQL
PawSQL is dedicated to automatic and intelligent database performance optimization. The products provided by PawSQL include:
- PawSQL Cloud, an online automated SQL optimization tool that supports SQL auditing, intelligent query rewriting, cost-based index recommendations, suitable for database administrators and data application developers.
- PawSQL Advisor, an IntelliJ plugin that is suitable for data application developers and can be installed via the IDEA/DataGrip marketplace by searching for "PawSQL Advisor" by name.
Contact Us
Email: service@pawsql.com
Website: https://www.pawsql.com