Four Pitfalls of SQL Processing with Null Values
Channel of advanced SQL tuning
Overview
NULL value processing is the most error-prone for database application developers, mainly because we are accustomed to using binary Boolean logic, while the database's processing logic for NULL values is three-valued logic. In fact, the most flawed component in the database optimizers is the logic related to NULL value processing. Even mature database software, such as DB2/Teradata, still has more than 20% of the bugs related NULL processing.
In this article, we analyze the root causes of the NULL value pitfalls, and conclude with a simple and effective examination logic to infer the final result. At the same time, we explain the applicable conditions and solutions for the four common scenarios in daily development work. After reading this article, you will be able to cope with all the scenarios regarding NULL value handling in your daily SQL processing work.
Code of Examination
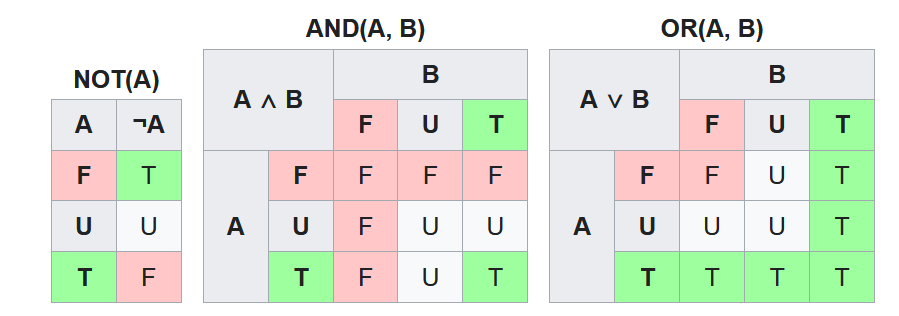
The following examination logic covers all scenarios for NULL values in SQL processing, and by understanding the following logic, you can avoid the NULL pitfalls.
1. The result of all comparison and arithmetic operators (>, =, <, !=, <=, >=, +,-,*, /) with `NULL` result is `unknown`
2. The logical operations(`AND, OR, NOT`) of `unknown` follows the [truth values table of three-value operations]
3. If the result of the operation is returned directly to the user, use `NULL` to represent `unknown`
4. If the result of the operation is `true` or `false` as a condition during SQL processing, then the operation needs to be performed by the three-value logic, and the final result is determined by the following logic
1. {false、unknown} -> false
2. {true} ->true
5. In set operations such as `UNION` or `INTERSECT`, `NULL` values are considered equal to each other.
Three-valued Logic 1
In logic, a three-valued logic (also trinary logic, trivalent, ternary, or trilean, sometimes abbreviated 3VL) is any of several many-valued logic systems in which there are three truth values indicating true, false and some indeterminate third value. This is contrasted with the more commonly known bivalent logics (such as classical sentential or Boolean logic) which provide only for true and false.
Pitfalls of NULL Value Processing
1. Comparison with NULL Values
Conclusion:
expr = nullcan’t determine the expressionexprto benull, andis nullshould be used to determine whether theexpris null.
Suppose there is a customer table with following five columns, among which two columns (c_nationcode,c_phone) are nullable.
CREATE TABLE customer (
c_custkey int4 NOT NULL,
c_name varchar(25) NOT NULL,
c_nationcode char(8) NULL,
c_phone varchar(15) NULL,
c_regdate date NULL,
CONSTRAINT customer_pkey PRIMARY KEY (c_custkey)
);
insert into customer values(1, 'Randy', 'en', '13910010010', '20210911');
insert into customer values(2, 'Mandy', null, '13910010012', '20200211');
insert into customer values(3, 'Ray', 'us', null, '20180902');
If a developer wants to find out the customers with empty phones through the following statement, he won't succeed because the result of following statement is always empty.
select * from customer where c_phone = null;
The correct way should be:
select * from customer where c_phone is null;
Let's examine according to the [Code of Examination], the predicate c_phone = null is evaluated to unknown; then according to Rule 4.1, unknown is treated as false.
c_phone=null
-> unknown
-> false;
2. Case When expression with NULL
Conclusion:
case expr when nullcan't determine if the expression is null, the correct way iscase when expr is null.
Problems in the where or having clause are easier to detect and correct, while it is much more difficult to detect null usages in case when expressions, either by human or by existing SQL auditing tools.
For example, if we want to decode the nation code to nation name, and the code is null, we want to set nation name to China:
select c_name, case c_nationcode
when 'us' then 'USA'
when 'cn' then 'China'
when null then 'China'
else 'Others' end
from customer
The above statement does not convert the country code to null to China. Because when null is actually an operation performed by an c_nationcode = null. The correct way to to do it should be:
select c_name, case when c_nationcode = 'us' then 'USA'
when c_nationcode = 'cn' then 'China'
when c_nationcode is null then 'China'
else 'Others' end
from customer
3. NOT IN with NULL
Conclusion A predicate of a
not insubquery with nullable select elements will always be evaluated to false.
Suppose we have an orders table where the customer id(o_custkey) and order date(o_orderdate) are nullable due to missing data.
CREATE TABLE orders (
o_orderkey int4 NOT NULL,
o_custkey int4 NULL,
o_orderdate date NULL,
CONSTRAINT orders_pkey PRIMARY KEY (o_orderkey)
);
insert into orders values(1, 1, '2021-01-01');
insert into orders values(2, null, '2020-09-01');
insert into orders values(3, 3, null);
Now we want to find customers without orders for marketing. The expected result is the customer whose c_custkey is 2, and the query statement might look like this,
select * from
customer
where c_custkey not in (
select o_custkey
from orders)
In fact, the above query return nothing to us. The reason is that the o_custkey in the subquery has null values, and the processing logic of NOT IN is like this
c_custkey not in (1,3,null)
→ c_custkey<>1 and c_custkey<>3 and c_custkey<>null
→ c_custkey<>1 and c_custkey<>3 and unknown
→ unknown
-> false
In fact, if there are null values in the result set of the subquery, the SQL will always return empty result set.
There are two correct ways:
Add a
NOT NULLpredicate to the subquery, that isselect *
from customer
where c_custkey not in (
select o_custkey
from orders
where o_custkey is not null
)Rewrite the
NOT INsubquery to thenot existssubquery, that isselect *
from customer
where not exists (
select o_custkey
from orders
where o_custkey=c_custkey
)
Note: PawSQL Advisor adopts the first method to do rewrite optimization, but it is more powerful, PawSQL Advisor first determines whether the columns in the subquery may be empty, and if it is possible, it will recommend the rewritten SQL to the user.
4. ALL Subquery with NULL
Conclusion: A condition of an
ALL-qualified subquery with nullable select elements will always be evaluated to false.
Suppose we want to find out the orders which are wrongly registered after the user is revoked. One of solution is this following query statement.
select *
from customer
where c_regdate > ALL (
select o_orderdate
from orders
where c_custkey = o_custkey
)
Similar to NOT IN above, this sql does not return the expected result due to the presence of NULL in the result of the subquery. The ALL operation is actually performed by comparing it with the returned result set, and then performing the AND operation, and the final result is unknown. While unknown as a condition to be evaluated is, the result is false.
There are two ways to correct it:
Add a
NOT NULLpredicate to the subquery,select *
from customer
where c_regdate > all(
select o_orderdate
from orders
where o_orderdate is not null
)Rewrite
expr > allto aggregate scalar subqueryexpr > (select max()...)2select *
from customer
where c_regdate > (
select max(o_custkey)
from orders
)
Note: PawSQL adopts the second way to rewrite optimization, because PawSQL can further optimize the performance of the second rewritten SQL by rewriting ('max/min subquery rewrite rule').
NULL Optimization in PawSQL
PawSQL has three rewrite optimization rules for NULL processing, corresponding to the four cases above.
| RuleCode | Rule Description |
|---|---|
| Use Equal for Null Rewrite | expr = null or case expr when null can't determine whether the expr is null , is null should be used |
| Not In Nullable SubQuery Rewrite | A predicate of a not in subquery with nullable select elements will always be evaluated to false. |
| All Qualified SubQuery Rewrite | A condition of an ALL-qualified subquery with nullable select elements will always be evaluated to false. |
PawSQL is more powerful. It will be based on whether the definition of a column in the DDL is nullable, or whether the operation on the column will produce nullable results, to determine whether the query column in the subquery is nullable, if it is possible to be empty, it will recommend the rewritten SQL to the user.
Rewrites by PawSQL
Case 1:
= nullrewritten tois null-- Original SQL
select count(*) from customer where c_phone = null;
-- Rewritten SQL
select count(*) from customer where customer.c_phone is null;Case 2:
case expr when nullrewritten ascase when expr is null-- Original SQL
select case c_phone
when null then 1
when '139%' then 0
else -1
end
from customer;
-- Rewritten SQL
select case
when c_phone is null then 1
when c_phone = '139%' then 0
else -1
end
from customer;Case 3:
c_nationkeyis nullable, add the conditionc_nationkey is not null-- Original SQL
select count(*)
from nation
where n_nationkey not in (
select c_nationkey
from customer)
-- Rewritten SQL
select count(*)
from nation
where n_nationkey not in (
select c_nationkey
from customer
where c_nationkey is not null)
Case 4:
c_nationkeyis nullable, somax(c_nationkey)is nullable, adding the conditionc_nationkey is not null-- Original SQL
select count(*)
from nation
where n_nationkey not in (
select max(c_nationkey)
from customer
group by c_mktsegment)
-- Rewritten SQL
select count(*)
from nation
where n_nationkey not in (
select max(customer.c_nationkey)
from customer
where c_nationkey is not null
group by c_mktsegment)Case 5:
count(c_nationkey)is never empty, so there is no need to rewrite it.select count(*)
from nation
where n_nationkey not in (
select count(c_nationkey)
from customer
group by c_mktsegment)Case 6:
c_nameis not empty, butc_nationkeyis nullable, so thec_nationkey is not nullcondition needs to be added.-- Original SQL
select count(*)
from nation
where (n_name,n_nationkey) not in (
select 'China',c_nationkey
from customer
);
-- Rewritten SQL
select count(*)
from nation
where(n_name, n_nationkey) not in (
select'China', c_nationkey
from customer
where customer.c_nationkey is not null)Case 7:
c_nationkeyis nullable, so rewritten as> (select min(c_nationkey) from customer)-- Original SQL
select count(*)
from customer
where n_nationkey > all(
select c_nationkey
from customer
);
-- Rewritten SQL
select count(*)
from customer
where n_nationkey > (
select min(c_nationkey)
from customer)
- https://en.wikipedia.org/wiki/Three-valued_logic↩
- If
expr < allorexpr < = all, then rewrite it asexpr < (select min() ...)↩