Introduction
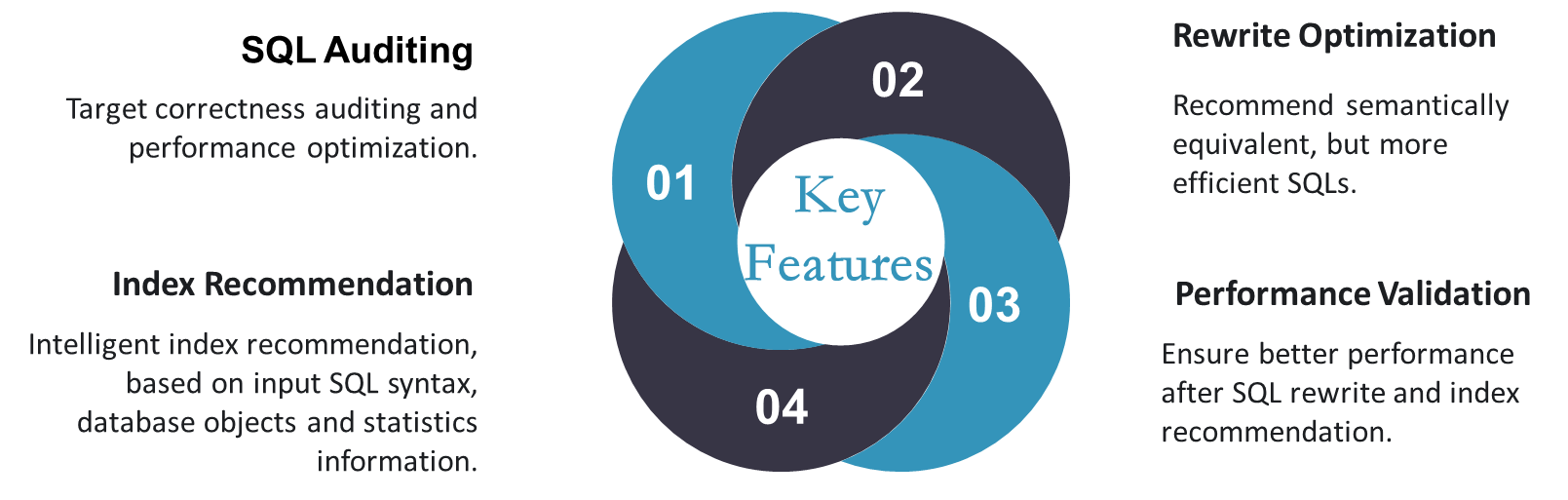
PawSQL integrates the best practices of query optimization in database industry, provides SQL auditing and rewrite optimization capability, and sophisticate index recommendation with the powerful intelligent Index Advisor engine for slow queries.
Key Features¶
Supported databases
PawSQL is based on a self-developed SQL parser and supports multiple database types and SQL dialects. The current supported database list is as follows, and it is still increasing...
